Note
Go to the end to download the full example code
Multiphysics property prediction from hyperspectral drill core data¶
This notebook uses drill core data to train a model that predicts petrophysical properties from hyperspectral data.j
import dotenv
import matplotlib.pyplot as plt
import numpy as np
import os
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
from sklearn.cluster import HDBSCAN
from sklearn.model_selection import StratifiedShuffleSplit
from tqdm import tqdm
import hklearn
We have prepared a Stack object with the hyperspectral and petrophysical data integrated into it Load the Stack
dotenv.load_dotenv()
base_path = os.getenv("PATH_TO_HyTorch")
S = hklearn.Stack.load(f"{base_path}/Training_Stack")
Python-dotenv could not parse statement starting at line 13
Python-dotenv could not parse statement starting at line 14
Python-dotenv could not parse statement starting at line 15
Python-dotenv could not parse statement starting at line 16
Python-dotenv could not parse statement starting at line 17
Get the spectra and properties (hklearn filters out the NaNs)
X = S.X() # Spectra
y = S.y() # Properties and their standard deviations
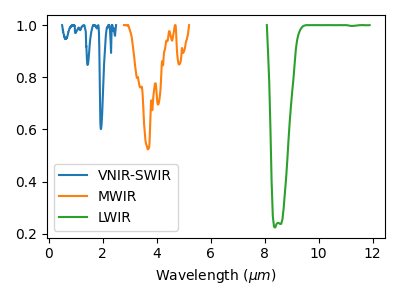
Visualize a single spectrum
plt.figure(figsize=(4, 3))
plt.plot(S.get_wavelengths("SWIR")/1e3, S.X("SWIR")[550])
plt.plot(S.get_wavelengths("MWIR")/1e3, S.X("MWIR")[550])
plt.plot(S.get_wavelengths("LWIR")/1e3, S.X("LWIR")[550])
plt.xlabel(r"Wavelength $(\mu m)$")
plt.legend(["VNIR-SWIR", "MWIR", "LWIR"])
plt.tight_layout()
plt.show()
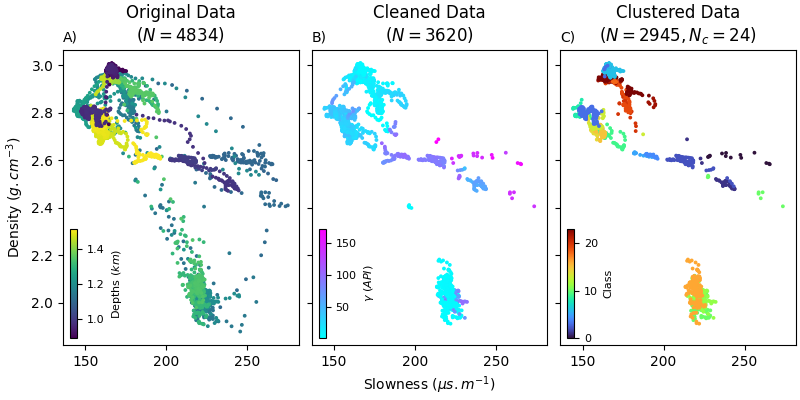
Step 1: Filtering¶
We do two steps of filtering: 1. We use the standard deviations to eliminate points with lithological contacts. 2. We use HDBSCAN to generate clusters based on the PCA of the spectra, which eliminates ‘noisy’ spectra that aren’t spectrally abundant
High variance filtering Remove the high variance points (Using the rolling standard deviations)
keep_idx = np.logical_and(S.y()[:, 4] < 5, np.logical_and(S.y()[:, 5] < 5e-2, S.y()[:, -1] < 1000))
X = X[keep_idx]
y = y[keep_idx, :4]
Clustering Fit a PCA
from hylite.filter import PCA
pca, loadings, _ = PCA(X, bands=30)
pca.data = pca.data/np.max(np.abs(pca.data), axis=0)[None, :]
# Init
clustering = HDBSCAN(10, 10)
# Fit + Predict
labels = clustering.fit_predict(np.c_[y[:, 0] * 1e-2, pca.data])
un_l, un_cts = np.unique(labels, return_counts=True)
Using matplotlib.pyplot to visualize the effect of the filtering and clustering
Plot the properties
fig, axs = plt.subplot_mosaic([['A)', 'B)', 'C)']], layout='constrained', sharey=True, sharex=True, figsize=(8, 4))
# Original Data
label = list(axs.keys())
ax = list(axs.values())
m = ax[0].scatter(S.y()[:, 1], S.y()[:, 2], c=S.y()[:, 0]/1e3, s=3)
ax[0].set_title(r"Original Data" + "\n" + r"$(N = %d)$" % S.y().shape[0])
ax[0].set_ylabel(r"Density $(g.cm^{-3})$")
ax[0].set_title(label[0], loc='left', fontsize='medium')
cbaxes = inset_axes(ax[0], width="3%", height="37%", loc=3)
cbaxes.tick_params(labelsize=8)
plt.colorbar(cax=cbaxes, mappable=m)
cbaxes.set_ylabel(r"Depths $(km)$", fontsize=8)
# Cleaned data
m1 = ax[1].scatter(y[:, 1], y[:, 2], c=y[:, -1], s=3, cmap="cool")
ax[1].set_title(r"Cleaned Data" + "\n" + r"$(N = %d)$" % y.shape[0])
ax[1].set_xlabel(r"Slowness $(\mu s.m^{-1})$")
ax[1].set_title(label[1], loc='left', fontsize='medium')
cbaxes = inset_axes(ax[1], width="3%", height="37%", loc=3)
cbaxes.tick_params(labelsize=8)
plt.colorbar(cax=cbaxes, mappable=m1)
cbaxes.set_ylabel(r"$\gamma$ $(API)$", fontsize=8)
# Labeled data
m2 = ax[2].scatter(y[labels >= 0., 1], y[labels >= 0., 2], c=labels[labels >= 0.], s=3, cmap="turbo")
ax[2].set_title(r"Clustered Data" + "\n" + r"$(N = %d, N_c = %d)$" % (np.sum(labels >= 0.), un_l.shape[0] - 1))
ax[2].set_title(label[2], loc='left', fontsize='medium')
cbaxes = inset_axes(ax[2], width="3%", height="37%", loc=3)
cbaxes.tick_params(labelsize=8)
plt.colorbar(cax=cbaxes, mappable=m2)
cbaxes.set_ylabel(r"Class", fontsize=8)
plt.show()
Step 2: Extract the hyperspectral data¶
Save the labeled data (Drop the NaNs)
fin_idx = labels >= 0.
# Complete spectrum
fin_X = 1 - S.X()[keep_idx][fin_idx]
# SWIR
fin_swir = 1 - S.X(sensor="SWIR")[keep_idx][fin_idx]
# MWIR
fin_mwir = 1 - S.X(sensor="MWIR")[keep_idx][fin_idx]
# LWIR
fin_lwir = 1 - S.X(sensor="LWIR")[keep_idx][fin_idx]
# Scale the properties to keep the order of magnitude the same
fin_y = S.y()[keep_idx][fin_idx, 1:4] * np.array([1e-3, 1e-1, 1e-3])[None, :]
# Labels
fin_lbls = labels[fin_idx].astype(int)
Step 3: Define a shuffled Train + Validation split¶
Use stratified shuffle splitting
n_splits = 6
test_size = 0.25
sss = StratifiedShuffleSplit(n_splits=n_splits,
test_size=test_size,
random_state=404)
idxs = np.arange(fin_lbls.shape[0])
train_idxs = []
valid_idxs = []
for train_idx, valid_idx in sss.split(idxs, fin_lbls):
train_idxs.append(train_idx)
valid_idxs.append(valid_idx)
# Stack
train_idxs = np.vstack(train_idxs)
valid_idxs = np.vstack(valid_idxs)
Step 4: Define a pytorch model¶
Torch
import torch
import torch.nn as nn
import torch.optim as optim
from torcheval.metrics import R2Score, MeanSquaredError
import copy
from torch.utils.data import Dataset, DataLoader
# Classes
# Dataset
class MultimodalDataset(Dataset):
def __init__(self, swir, mwir, lwir, labels, targets):
self.swir = swir
self.mwir = mwir
self.lwir = lwir
self.labels = labels
self.targets = targets
def __len__(self):
return len(self.targets)
def __getitem__(self, idx):
return self.swir[idx], self.mwir[idx], self.lwir[idx], self.labels[idx], self.targets[idx]
class WeightedMSELoss(nn.Module):
def __init__(self, non_neg_penalty_weight=1.0):
super(WeightedMSELoss, self).__init__()
self.non_neg_penalty_weight = non_neg_penalty_weight
def forward(self, inputs, weights, targets):
# Calculate the MSE loss for each example in the batch
mse_loss = (inputs - targets) ** 2
# Apply weights to the MSE loss
weighted_mse_loss = mse_loss * weights[:, None]
# Calculate the mean loss
loss = weighted_mse_loss.mean()
# Add non-negativity penalty
non_neg_penalty = self.non_neg_penalty_weight * torch.sum(torch.clamp(-inputs, min=0) ** 2)
total_loss = loss + non_neg_penalty
return total_loss
class MultiHeadedMLP(nn.Module):
def __init__(self, in_sizes, hidden_sizes, out_channels, output_size, conv_kernel_size=[3, 3, 3], conv_stride=1, conv_padding=1):
super(MultiHeadedMLP, self).__init__()
# Calculate output sizes after convolution
self.swir_conv_output_size = self._calculate_conv_output_size(in_sizes[0], conv_kernel_size[0], conv_stride, conv_padding)
self.mwir_conv_output_size = self._calculate_conv_output_size(in_sizes[1], conv_kernel_size[1], conv_stride, conv_padding)
self.lwir_conv_output_size = self._calculate_conv_output_size(in_sizes[2], conv_kernel_size[2], conv_stride, conv_padding)
# Define separate input heads for each band type with a conv layer
self.swir_head = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=out_channels, kernel_size=conv_kernel_size[0], stride=conv_stride, padding=conv_padding),
nn.ReLU(),
nn.Flatten(),
nn.Linear(self.swir_conv_output_size * out_channels, hidden_sizes[0]),
nn.ReLU(),
)
self.mwir_head = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=out_channels, kernel_size=conv_kernel_size[1], stride=conv_stride, padding=conv_padding),
nn.ReLU(),
nn.Flatten(),
nn.Linear(self.mwir_conv_output_size * out_channels, hidden_sizes[1]),
nn.ReLU(),
)
self.lwir_head = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=out_channels, kernel_size=conv_kernel_size[2], stride=conv_stride, padding=conv_padding),
nn.ReLU(),
nn.Flatten(),
nn.Linear(self.lwir_conv_output_size * out_channels, hidden_sizes[2]),
nn.ReLU(),
)
# Define a shared hidden layer after combining the inputs
combined_input_size = hidden_sizes[0] + hidden_sizes[1] + hidden_sizes[2]
self.shared_layer = nn.Sequential(
nn.Linear(combined_input_size, combined_input_size * 2),
nn.ReLU(),
nn.Linear(combined_input_size * 2, combined_input_size // 2),
nn.ReLU(),
nn.Linear(combined_input_size // 2, 16),
nn.ReLU(),
nn.Linear(16, output_size),
)
def _calculate_conv_output_size(self, input_size, kernel_size, stride, padding):
return (input_size - kernel_size + 2 * padding) // stride + 1
def forward(self, swir, mwir, lwir):
# Add channel dimension for conv layer
swir = swir.unsqueeze(1)
mwir = mwir.unsqueeze(1)
lwir = lwir.unsqueeze(1)
swir_out = self.swir_head(swir)
mwir_out = self.mwir_head(mwir)
lwir_out = self.lwir_head(lwir)
# Concatenate the outputs from each head
combined = torch.cat((swir_out, mwir_out, lwir_out), dim=1)
# Pass through the shared layer
output = self.shared_layer(combined)
return output
Initialize the model and prepare for training
Make datasets
batch_size = 10
# Initialize a model
hidden_sizes = [32, 32, 32]
in_sizes = [S.X(sensor).shape[1] for sensor in S.get_sensors()]
output_size = 3
conv_kernel_size = [60, 40, 20]
conv_stride = 1
conv_padding = 1
out_channels = 4
model = MultiHeadedMLP(in_sizes, hidden_sizes,
out_channels, output_size,
conv_kernel_size, conv_stride,
conv_padding)
# Loss Function
wt_loss_fn = WeightedMSELoss(non_neg_penalty_weight=2)
loss_fn = nn.MSELoss()
# Optimizer
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# Number of training epochs (Per fold)
n_epochs = 100
# Initialize parameters
best_mse = np.inf
best_weights = None
train_history = []
history = []
Training¶
Begin Training
for j in range(n_splits):
# Fold training
train_idx = train_idxs[j]
# Fold Validation
valid_idx = valid_idxs[j]
# Get the separated datasets
# Training
train_X, train_swir, train_mwir, train_lwir, train_y = torch.Tensor(fin_X[train_idx]), torch.Tensor(fin_swir[train_idx]), torch.Tensor(fin_mwir[train_idx]), torch.Tensor(fin_lwir[train_idx]), torch.Tensor(fin_y[train_idx])
# Validation
valid_X, valid_swir, valid_mwir, valid_lwir, valid_y = torch.Tensor(fin_X[valid_idx]), torch.Tensor(fin_swir[valid_idx]), torch.Tensor(fin_mwir[valid_idx]), torch.Tensor(fin_lwir[valid_idx]), torch.Tensor(fin_y[valid_idx])
# Compute the weights
fold_idxs = [train_idx, valid_idx]
weights = []
for i in range(2):
# Define the weights
lbls, counts = np.unique(fin_lbls[fold_idxs[i]], return_counts=True)
counts = 1/counts
class_weights = counts/counts.sum()
# Assign the weights
loss_weights = np.array([class_weights[fin_lbls[i] == lbls] for i in range(fin_lbls[fold_idxs[i]].shape[0])])
weights.append(torch.Tensor(loss_weights))
train_dataset = MultimodalDataset(train_swir, train_mwir, train_lwir, weights[0], train_y)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
with tqdm(range(n_epochs), unit=" epochs", mininterval=0, disable=False) as bar_:
bar_.set_description(f"Training Fold {j + 1}")
for epoch in bar_:
model.train()
with tqdm(train_loader, unit="batch", mininterval=0, disable=True) as bar:
bar.set_description(f"Epoch {epoch}")
for batch_swir, batch_mwir, batch_lwir, batch_weights, y_batch in bar:
# Forward pass
y_pred = model(batch_swir, batch_mwir, batch_lwir)
# Calculate Loss
loss = wt_loss_fn(y_pred, batch_weights, y_batch)
# Backward pass
optimizer.zero_grad()
loss.backward()
# Update weights
optimizer.step()
# Log training loss for the epoch
train_pred = model(train_swir, train_mwir, train_lwir)
train_mse = loss_fn(train_pred, train_y)
train_history.append(train_mse.item())
# Validation Loss
valid_pred = model(valid_swir, valid_mwir, valid_lwir)
mse = loss_fn(valid_pred, valid_y)
history.append(mse.item())
if mse.item() < best_mse:
best_mse = mse.item()
best_weights = copy.deepcopy(model.state_dict())
# Print progress
bar_.set_postfix({"Training Loss" : train_mse.item(), "Validation Loss": mse.item(), "Best Loss": best_mse})
# Restore model with best weights
model.load_state_dict(best_weights)
0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 1: 0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 1: 0%| | 0/100 [00:01<?, ? epochs/s, Training Loss=0.000802, Validation Loss=0.000815, Best Loss=0.000815]
Training Fold 1: 1%| | 1/100 [00:01<02:24, 1.46s/ epochs, Training Loss=0.000802, Validation Loss=0.000815, Best Loss=0.000815]
Training Fold 1: 1%| | 1/100 [00:02<02:24, 1.46s/ epochs, Training Loss=0.000271, Validation Loss=0.000268, Best Loss=0.000268]
Training Fold 1: 2%|▏ | 2/100 [00:02<01:32, 1.05 epochs/s, Training Loss=0.000271, Validation Loss=0.000268, Best Loss=0.000268]
Training Fold 1: 2%|▏ | 2/100 [00:02<01:32, 1.05 epochs/s, Training Loss=0.000143, Validation Loss=0.000136, Best Loss=0.000136]
Training Fold 1: 3%|▎ | 3/100 [00:02<01:12, 1.34 epochs/s, Training Loss=0.000143, Validation Loss=0.000136, Best Loss=0.000136]
Training Fold 1: 3%|▎ | 3/100 [00:03<01:12, 1.34 epochs/s, Training Loss=0.000147, Validation Loss=0.00014, Best Loss=0.000136]
Training Fold 1: 4%|▍ | 4/100 [00:03<01:01, 1.55 epochs/s, Training Loss=0.000147, Validation Loss=0.00014, Best Loss=0.000136]
Training Fold 1: 4%|▍ | 4/100 [00:03<01:01, 1.55 epochs/s, Training Loss=0.00011, Validation Loss=0.000107, Best Loss=0.000107]
Training Fold 1: 5%|▌ | 5/100 [00:03<00:56, 1.68 epochs/s, Training Loss=0.00011, Validation Loss=0.000107, Best Loss=0.000107]
Training Fold 1: 5%|▌ | 5/100 [00:04<00:56, 1.68 epochs/s, Training Loss=0.000105, Validation Loss=0.000101, Best Loss=0.000101]
Training Fold 1: 6%|▌ | 6/100 [00:04<00:52, 1.80 epochs/s, Training Loss=0.000105, Validation Loss=0.000101, Best Loss=0.000101]
Training Fold 1: 6%|▌ | 6/100 [00:04<00:52, 1.80 epochs/s, Training Loss=0.000109, Validation Loss=0.000104, Best Loss=0.000101]
Training Fold 1: 7%|▋ | 7/100 [00:04<00:49, 1.89 epochs/s, Training Loss=0.000109, Validation Loss=0.000104, Best Loss=0.000101]
Training Fold 1: 7%|▋ | 7/100 [00:05<00:49, 1.89 epochs/s, Training Loss=9.32e-5, Validation Loss=8.96e-5, Best Loss=8.96e-5]
Training Fold 1: 8%|▊ | 8/100 [00:05<00:48, 1.89 epochs/s, Training Loss=9.32e-5, Validation Loss=8.96e-5, Best Loss=8.96e-5]
Training Fold 1: 8%|▊ | 8/100 [00:05<00:48, 1.89 epochs/s, Training Loss=9.39e-5, Validation Loss=9.16e-5, Best Loss=8.96e-5]
Training Fold 1: 9%|▉ | 9/100 [00:05<00:46, 1.95 epochs/s, Training Loss=9.39e-5, Validation Loss=9.16e-5, Best Loss=8.96e-5]
Training Fold 1: 9%|▉ | 9/100 [00:06<00:46, 1.95 epochs/s, Training Loss=8.68e-5, Validation Loss=8.29e-5, Best Loss=8.29e-5]
Training Fold 1: 10%|█ | 10/100 [00:06<00:45, 1.96 epochs/s, Training Loss=8.68e-5, Validation Loss=8.29e-5, Best Loss=8.29e-5]
Training Fold 1: 10%|█ | 10/100 [00:06<00:45, 1.96 epochs/s, Training Loss=8.41e-5, Validation Loss=8.12e-5, Best Loss=8.12e-5]
Training Fold 1: 11%|█ | 11/100 [00:06<00:44, 2.00 epochs/s, Training Loss=8.41e-5, Validation Loss=8.12e-5, Best Loss=8.12e-5]
Training Fold 1: 11%|█ | 11/100 [00:06<00:44, 2.00 epochs/s, Training Loss=8.33e-5, Validation Loss=8e-5, Best Loss=8e-5]
Training Fold 1: 12%|█▏ | 12/100 [00:06<00:43, 2.01 epochs/s, Training Loss=8.33e-5, Validation Loss=8e-5, Best Loss=8e-5]
Training Fold 1: 12%|█▏ | 12/100 [00:07<00:43, 2.01 epochs/s, Training Loss=8.09e-5, Validation Loss=7.81e-5, Best Loss=7.81e-5]
Training Fold 1: 13%|█▎ | 13/100 [00:07<00:44, 1.97 epochs/s, Training Loss=8.09e-5, Validation Loss=7.81e-5, Best Loss=7.81e-5]
Training Fold 1: 13%|█▎ | 13/100 [00:08<00:44, 1.97 epochs/s, Training Loss=7.53e-5, Validation Loss=7.2e-5, Best Loss=7.2e-5]
Training Fold 1: 14%|█▍ | 14/100 [00:08<00:43, 1.98 epochs/s, Training Loss=7.53e-5, Validation Loss=7.2e-5, Best Loss=7.2e-5]
Training Fold 1: 14%|█▍ | 14/100 [00:08<00:43, 1.98 epochs/s, Training Loss=7.43e-5, Validation Loss=7.04e-5, Best Loss=7.04e-5]
Training Fold 1: 15%|█▌ | 15/100 [00:08<00:43, 1.95 epochs/s, Training Loss=7.43e-5, Validation Loss=7.04e-5, Best Loss=7.04e-5]
Training Fold 1: 15%|█▌ | 15/100 [00:09<00:43, 1.95 epochs/s, Training Loss=7.05e-5, Validation Loss=6.7e-5, Best Loss=6.7e-5]
Training Fold 1: 16%|█▌ | 16/100 [00:09<00:42, 1.97 epochs/s, Training Loss=7.05e-5, Validation Loss=6.7e-5, Best Loss=6.7e-5]
Training Fold 1: 16%|█▌ | 16/100 [00:09<00:42, 1.97 epochs/s, Training Loss=6.82e-5, Validation Loss=6.46e-5, Best Loss=6.46e-5]
Training Fold 1: 17%|█▋ | 17/100 [00:09<00:41, 2.01 epochs/s, Training Loss=6.82e-5, Validation Loss=6.46e-5, Best Loss=6.46e-5]
Training Fold 1: 17%|█▋ | 17/100 [00:09<00:41, 2.01 epochs/s, Training Loss=6.48e-5, Validation Loss=6.08e-5, Best Loss=6.08e-5]
Training Fold 1: 18%|█▊ | 18/100 [00:09<00:40, 2.04 epochs/s, Training Loss=6.48e-5, Validation Loss=6.08e-5, Best Loss=6.08e-5]
Training Fold 1: 18%|█▊ | 18/100 [00:10<00:40, 2.04 epochs/s, Training Loss=0.000147, Validation Loss=0.000139, Best Loss=6.08e-5]
Training Fold 1: 19%|█▉ | 19/100 [00:10<00:40, 2.02 epochs/s, Training Loss=0.000147, Validation Loss=0.000139, Best Loss=6.08e-5]
Training Fold 1: 19%|█▉ | 19/100 [00:10<00:40, 2.02 epochs/s, Training Loss=0.00012, Validation Loss=0.000118, Best Loss=6.08e-5]
Training Fold 1: 20%|██ | 20/100 [00:10<00:39, 2.03 epochs/s, Training Loss=0.00012, Validation Loss=0.000118, Best Loss=6.08e-5]
Training Fold 1: 20%|██ | 20/100 [00:11<00:39, 2.03 epochs/s, Training Loss=6.28e-5, Validation Loss=5.97e-5, Best Loss=5.97e-5]
Training Fold 1: 21%|██ | 21/100 [00:11<00:39, 2.01 epochs/s, Training Loss=6.28e-5, Validation Loss=5.97e-5, Best Loss=5.97e-5]
Training Fold 1: 21%|██ | 21/100 [00:11<00:39, 2.01 epochs/s, Training Loss=5.98e-5, Validation Loss=5.61e-5, Best Loss=5.61e-5]
Training Fold 1: 22%|██▏ | 22/100 [00:11<00:38, 2.01 epochs/s, Training Loss=5.98e-5, Validation Loss=5.61e-5, Best Loss=5.61e-5]
Training Fold 1: 22%|██▏ | 22/100 [00:12<00:38, 2.01 epochs/s, Training Loss=5.81e-5, Validation Loss=5.5e-5, Best Loss=5.5e-5]
Training Fold 1: 23%|██▎ | 23/100 [00:12<00:38, 2.00 epochs/s, Training Loss=5.81e-5, Validation Loss=5.5e-5, Best Loss=5.5e-5]
Training Fold 1: 23%|██▎ | 23/100 [00:12<00:38, 2.00 epochs/s, Training Loss=0.000189, Validation Loss=0.000185, Best Loss=5.5e-5]
Training Fold 1: 24%|██▍ | 24/100 [00:12<00:37, 2.02 epochs/s, Training Loss=0.000189, Validation Loss=0.000185, Best Loss=5.5e-5]
Training Fold 1: 24%|██▍ | 24/100 [00:13<00:37, 2.02 epochs/s, Training Loss=5.55e-5, Validation Loss=5.37e-5, Best Loss=5.37e-5]
Training Fold 1: 25%|██▌ | 25/100 [00:13<00:36, 2.06 epochs/s, Training Loss=5.55e-5, Validation Loss=5.37e-5, Best Loss=5.37e-5]
Training Fold 1: 25%|██▌ | 25/100 [00:13<00:36, 2.06 epochs/s, Training Loss=5.22e-5, Validation Loss=4.87e-5, Best Loss=4.87e-5]
Training Fold 1: 26%|██▌ | 26/100 [00:13<00:36, 2.03 epochs/s, Training Loss=5.22e-5, Validation Loss=4.87e-5, Best Loss=4.87e-5]
Training Fold 1: 26%|██▌ | 26/100 [00:14<00:36, 2.03 epochs/s, Training Loss=4.91e-5, Validation Loss=4.53e-5, Best Loss=4.53e-5]
Training Fold 1: 27%|██▋ | 27/100 [00:14<00:36, 2.03 epochs/s, Training Loss=4.91e-5, Validation Loss=4.53e-5, Best Loss=4.53e-5]
Training Fold 1: 27%|██▋ | 27/100 [00:14<00:36, 2.03 epochs/s, Training Loss=4.82e-5, Validation Loss=4.47e-5, Best Loss=4.47e-5]
Training Fold 1: 28%|██▊ | 28/100 [00:14<00:36, 1.99 epochs/s, Training Loss=4.82e-5, Validation Loss=4.47e-5, Best Loss=4.47e-5]
Training Fold 1: 28%|██▊ | 28/100 [00:15<00:36, 1.99 epochs/s, Training Loss=4.66e-5, Validation Loss=4.42e-5, Best Loss=4.42e-5]
Training Fold 1: 29%|██▉ | 29/100 [00:15<00:35, 2.01 epochs/s, Training Loss=4.66e-5, Validation Loss=4.42e-5, Best Loss=4.42e-5]
Training Fold 1: 29%|██▉ | 29/100 [00:15<00:35, 2.01 epochs/s, Training Loss=4.38e-5, Validation Loss=4.25e-5, Best Loss=4.25e-5]
Training Fold 1: 30%|███ | 30/100 [00:15<00:34, 2.03 epochs/s, Training Loss=4.38e-5, Validation Loss=4.25e-5, Best Loss=4.25e-5]
Training Fold 1: 30%|███ | 30/100 [00:16<00:34, 2.03 epochs/s, Training Loss=4.45e-5, Validation Loss=4.35e-5, Best Loss=4.25e-5]
Training Fold 1: 31%|███ | 31/100 [00:16<00:33, 2.04 epochs/s, Training Loss=4.45e-5, Validation Loss=4.35e-5, Best Loss=4.25e-5]
Training Fold 1: 31%|███ | 31/100 [00:16<00:33, 2.04 epochs/s, Training Loss=4.45e-5, Validation Loss=4.43e-5, Best Loss=4.25e-5]
Training Fold 1: 32%|███▏ | 32/100 [00:16<00:33, 2.05 epochs/s, Training Loss=4.45e-5, Validation Loss=4.43e-5, Best Loss=4.25e-5]
Training Fold 1: 32%|███▏ | 32/100 [00:17<00:33, 2.05 epochs/s, Training Loss=4.24e-5, Validation Loss=4.01e-5, Best Loss=4.01e-5]
Training Fold 1: 33%|███▎ | 33/100 [00:17<00:32, 2.09 epochs/s, Training Loss=4.24e-5, Validation Loss=4.01e-5, Best Loss=4.01e-5]
Training Fold 1: 33%|███▎ | 33/100 [00:17<00:32, 2.09 epochs/s, Training Loss=4.63e-5, Validation Loss=4.6e-5, Best Loss=4.01e-5]
Training Fold 1: 34%|███▍ | 34/100 [00:17<00:31, 2.10 epochs/s, Training Loss=4.63e-5, Validation Loss=4.6e-5, Best Loss=4.01e-5]
Training Fold 1: 34%|███▍ | 34/100 [00:18<00:31, 2.10 epochs/s, Training Loss=4.22e-5, Validation Loss=3.92e-5, Best Loss=3.92e-5]
Training Fold 1: 35%|███▌ | 35/100 [00:18<00:31, 2.09 epochs/s, Training Loss=4.22e-5, Validation Loss=3.92e-5, Best Loss=3.92e-5]
Training Fold 1: 35%|███▌ | 35/100 [00:18<00:31, 2.09 epochs/s, Training Loss=4.24e-5, Validation Loss=4.21e-5, Best Loss=3.92e-5]
Training Fold 1: 36%|███▌ | 36/100 [00:18<00:30, 2.10 epochs/s, Training Loss=4.24e-5, Validation Loss=4.21e-5, Best Loss=3.92e-5]
Training Fold 1: 36%|███▌ | 36/100 [00:19<00:30, 2.10 epochs/s, Training Loss=3.89e-5, Validation Loss=3.67e-5, Best Loss=3.67e-5]
Training Fold 1: 37%|███▋ | 37/100 [00:19<00:29, 2.11 epochs/s, Training Loss=3.89e-5, Validation Loss=3.67e-5, Best Loss=3.67e-5]
Training Fold 1: 37%|███▋ | 37/100 [00:19<00:29, 2.11 epochs/s, Training Loss=4.47e-5, Validation Loss=4.27e-5, Best Loss=3.67e-5]
Training Fold 1: 38%|███▊ | 38/100 [00:19<00:29, 2.07 epochs/s, Training Loss=4.47e-5, Validation Loss=4.27e-5, Best Loss=3.67e-5]
Training Fold 1: 38%|███▊ | 38/100 [00:20<00:29, 2.07 epochs/s, Training Loss=3.83e-5, Validation Loss=3.72e-5, Best Loss=3.67e-5]
Training Fold 1: 39%|███▉ | 39/100 [00:20<00:29, 2.08 epochs/s, Training Loss=3.83e-5, Validation Loss=3.72e-5, Best Loss=3.67e-5]
Training Fold 1: 39%|███▉ | 39/100 [00:20<00:29, 2.08 epochs/s, Training Loss=4.31e-5, Validation Loss=4.02e-5, Best Loss=3.67e-5]
Training Fold 1: 40%|████ | 40/100 [00:20<00:29, 2.06 epochs/s, Training Loss=4.31e-5, Validation Loss=4.02e-5, Best Loss=3.67e-5]
Training Fold 1: 40%|████ | 40/100 [00:21<00:29, 2.06 epochs/s, Training Loss=6.61e-5, Validation Loss=6.25e-5, Best Loss=3.67e-5]
Training Fold 1: 41%|████ | 41/100 [00:21<00:28, 2.08 epochs/s, Training Loss=6.61e-5, Validation Loss=6.25e-5, Best Loss=3.67e-5]
Training Fold 1: 41%|████ | 41/100 [00:21<00:28, 2.08 epochs/s, Training Loss=3.37e-5, Validation Loss=3.15e-5, Best Loss=3.15e-5]
Training Fold 1: 42%|████▏ | 42/100 [00:21<00:27, 2.10 epochs/s, Training Loss=3.37e-5, Validation Loss=3.15e-5, Best Loss=3.15e-5]
Training Fold 1: 42%|████▏ | 42/100 [00:22<00:27, 2.10 epochs/s, Training Loss=3.53e-5, Validation Loss=3.34e-5, Best Loss=3.15e-5]
Training Fold 1: 43%|████▎ | 43/100 [00:22<00:27, 2.05 epochs/s, Training Loss=3.53e-5, Validation Loss=3.34e-5, Best Loss=3.15e-5]
Training Fold 1: 43%|████▎ | 43/100 [00:22<00:27, 2.05 epochs/s, Training Loss=4.34e-5, Validation Loss=4.21e-5, Best Loss=3.15e-5]
Training Fold 1: 44%|████▍ | 44/100 [00:22<00:27, 2.07 epochs/s, Training Loss=4.34e-5, Validation Loss=4.21e-5, Best Loss=3.15e-5]
Training Fold 1: 44%|████▍ | 44/100 [00:23<00:27, 2.07 epochs/s, Training Loss=9.39e-5, Validation Loss=9.12e-5, Best Loss=3.15e-5]
Training Fold 1: 45%|████▌ | 45/100 [00:23<00:26, 2.08 epochs/s, Training Loss=9.39e-5, Validation Loss=9.12e-5, Best Loss=3.15e-5]
Training Fold 1: 45%|████▌ | 45/100 [00:23<00:26, 2.08 epochs/s, Training Loss=3.4e-5, Validation Loss=3.3e-5, Best Loss=3.15e-5]
Training Fold 1: 46%|████▌ | 46/100 [00:23<00:26, 2.05 epochs/s, Training Loss=3.4e-5, Validation Loss=3.3e-5, Best Loss=3.15e-5]
Training Fold 1: 46%|████▌ | 46/100 [00:24<00:26, 2.05 epochs/s, Training Loss=3.34e-5, Validation Loss=2.96e-5, Best Loss=2.96e-5]
Training Fold 1: 47%|████▋ | 47/100 [00:24<00:25, 2.09 epochs/s, Training Loss=3.34e-5, Validation Loss=2.96e-5, Best Loss=2.96e-5]
Training Fold 1: 47%|████▋ | 47/100 [00:24<00:25, 2.09 epochs/s, Training Loss=3.26e-5, Validation Loss=3.06e-5, Best Loss=2.96e-5]
Training Fold 1: 48%|████▊ | 48/100 [00:24<00:24, 2.09 epochs/s, Training Loss=3.26e-5, Validation Loss=3.06e-5, Best Loss=2.96e-5]
Training Fold 1: 48%|████▊ | 48/100 [00:25<00:24, 2.09 epochs/s, Training Loss=3.58e-5, Validation Loss=3.62e-5, Best Loss=2.96e-5]
Training Fold 1: 49%|████▉ | 49/100 [00:25<00:24, 2.12 epochs/s, Training Loss=3.58e-5, Validation Loss=3.62e-5, Best Loss=2.96e-5]
Training Fold 1: 49%|████▉ | 49/100 [00:25<00:24, 2.12 epochs/s, Training Loss=3.76e-5, Validation Loss=3.81e-5, Best Loss=2.96e-5]
Training Fold 1: 50%|█████ | 50/100 [00:25<00:23, 2.09 epochs/s, Training Loss=3.76e-5, Validation Loss=3.81e-5, Best Loss=2.96e-5]
Training Fold 1: 50%|█████ | 50/100 [00:26<00:23, 2.09 epochs/s, Training Loss=3.39e-5, Validation Loss=3.02e-5, Best Loss=2.96e-5]
Training Fold 1: 51%|█████ | 51/100 [00:26<00:23, 2.07 epochs/s, Training Loss=3.39e-5, Validation Loss=3.02e-5, Best Loss=2.96e-5]
Training Fold 1: 51%|█████ | 51/100 [00:26<00:23, 2.07 epochs/s, Training Loss=3.26e-5, Validation Loss=3.22e-5, Best Loss=2.96e-5]
Training Fold 1: 52%|█████▏ | 52/100 [00:26<00:23, 2.07 epochs/s, Training Loss=3.26e-5, Validation Loss=3.22e-5, Best Loss=2.96e-5]
Training Fold 1: 52%|█████▏ | 52/100 [00:26<00:23, 2.07 epochs/s, Training Loss=5.04e-5, Validation Loss=4.76e-5, Best Loss=2.96e-5]
Training Fold 1: 53%|█████▎ | 53/100 [00:26<00:22, 2.05 epochs/s, Training Loss=5.04e-5, Validation Loss=4.76e-5, Best Loss=2.96e-5]
Training Fold 1: 53%|█████▎ | 53/100 [00:27<00:22, 2.05 epochs/s, Training Loss=3.24e-5, Validation Loss=2.75e-5, Best Loss=2.75e-5]
Training Fold 1: 54%|█████▍ | 54/100 [00:27<00:21, 2.11 epochs/s, Training Loss=3.24e-5, Validation Loss=2.75e-5, Best Loss=2.75e-5]
Training Fold 1: 54%|█████▍ | 54/100 [00:27<00:21, 2.11 epochs/s, Training Loss=2.9e-5, Validation Loss=2.75e-5, Best Loss=2.75e-5]
Training Fold 1: 55%|█████▌ | 55/100 [00:27<00:21, 2.09 epochs/s, Training Loss=2.9e-5, Validation Loss=2.75e-5, Best Loss=2.75e-5]
Training Fold 1: 55%|█████▌ | 55/100 [00:28<00:21, 2.09 epochs/s, Training Loss=2.91e-5, Validation Loss=2.84e-5, Best Loss=2.75e-5]
Training Fold 1: 56%|█████▌ | 56/100 [00:28<00:20, 2.13 epochs/s, Training Loss=2.91e-5, Validation Loss=2.84e-5, Best Loss=2.75e-5]
Training Fold 1: 56%|█████▌ | 56/100 [00:28<00:20, 2.13 epochs/s, Training Loss=3.75e-5, Validation Loss=3.64e-5, Best Loss=2.75e-5]
Training Fold 1: 57%|█████▋ | 57/100 [00:28<00:20, 2.10 epochs/s, Training Loss=3.75e-5, Validation Loss=3.64e-5, Best Loss=2.75e-5]
Training Fold 1: 57%|█████▋ | 57/100 [00:29<00:20, 2.10 epochs/s, Training Loss=2.95e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 58%|█████▊ | 58/100 [00:29<00:19, 2.10 epochs/s, Training Loss=2.95e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 58%|█████▊ | 58/100 [00:29<00:19, 2.10 epochs/s, Training Loss=2.88e-5, Validation Loss=2.94e-5, Best Loss=2.68e-5]
Training Fold 1: 59%|█████▉ | 59/100 [00:29<00:20, 2.00 epochs/s, Training Loss=2.88e-5, Validation Loss=2.94e-5, Best Loss=2.68e-5]
Training Fold 1: 59%|█████▉ | 59/100 [00:30<00:20, 2.00 epochs/s, Training Loss=2.91e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 60%|██████ | 60/100 [00:30<00:20, 1.97 epochs/s, Training Loss=2.91e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 60%|██████ | 60/100 [00:30<00:20, 1.97 epochs/s, Training Loss=2.93e-5, Validation Loss=2.85e-5, Best Loss=2.68e-5]
Training Fold 1: 61%|██████ | 61/100 [00:30<00:19, 1.97 epochs/s, Training Loss=2.93e-5, Validation Loss=2.85e-5, Best Loss=2.68e-5]
Training Fold 1: 61%|██████ | 61/100 [00:31<00:19, 1.97 epochs/s, Training Loss=3.23e-5, Validation Loss=3.16e-5, Best Loss=2.68e-5]
Training Fold 1: 62%|██████▏ | 62/100 [00:31<00:19, 1.93 epochs/s, Training Loss=3.23e-5, Validation Loss=3.16e-5, Best Loss=2.68e-5]
Training Fold 1: 62%|██████▏ | 62/100 [00:31<00:19, 1.93 epochs/s, Training Loss=3.05e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 63%|██████▎ | 63/100 [00:31<00:18, 1.98 epochs/s, Training Loss=3.05e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 63%|██████▎ | 63/100 [00:32<00:18, 1.98 epochs/s, Training Loss=2.72e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 64%|██████▍ | 64/100 [00:32<00:17, 2.03 epochs/s, Training Loss=2.72e-5, Validation Loss=2.68e-5, Best Loss=2.68e-5]
Training Fold 1: 64%|██████▍ | 64/100 [00:32<00:17, 2.03 epochs/s, Training Loss=3.55e-5, Validation Loss=3.67e-5, Best Loss=2.68e-5]
Training Fold 1: 65%|██████▌ | 65/100 [00:32<00:17, 2.03 epochs/s, Training Loss=3.55e-5, Validation Loss=3.67e-5, Best Loss=2.68e-5]
Training Fold 1: 65%|██████▌ | 65/100 [00:33<00:17, 2.03 epochs/s, Training Loss=2.93e-5, Validation Loss=2.83e-5, Best Loss=2.68e-5]
Training Fold 1: 66%|██████▌ | 66/100 [00:33<00:16, 2.01 epochs/s, Training Loss=2.93e-5, Validation Loss=2.83e-5, Best Loss=2.68e-5]
Training Fold 1: 66%|██████▌ | 66/100 [00:33<00:16, 2.01 epochs/s, Training Loss=2.68e-5, Validation Loss=2.59e-5, Best Loss=2.59e-5]
Training Fold 1: 67%|██████▋ | 67/100 [00:33<00:16, 2.01 epochs/s, Training Loss=2.68e-5, Validation Loss=2.59e-5, Best Loss=2.59e-5]
Training Fold 1: 67%|██████▋ | 67/100 [00:34<00:16, 2.01 epochs/s, Training Loss=2.64e-5, Validation Loss=2.51e-5, Best Loss=2.51e-5]
Training Fold 1: 68%|██████▊ | 68/100 [00:34<00:15, 2.03 epochs/s, Training Loss=2.64e-5, Validation Loss=2.51e-5, Best Loss=2.51e-5]
Training Fold 1: 68%|██████▊ | 68/100 [00:34<00:15, 2.03 epochs/s, Training Loss=6.17e-5, Validation Loss=6.24e-5, Best Loss=2.51e-5]
Training Fold 1: 69%|██████▉ | 69/100 [00:34<00:15, 2.03 epochs/s, Training Loss=6.17e-5, Validation Loss=6.24e-5, Best Loss=2.51e-5]
Training Fold 1: 69%|██████▉ | 69/100 [00:35<00:15, 2.03 epochs/s, Training Loss=3.05e-5, Validation Loss=3.05e-5, Best Loss=2.51e-5]
Training Fold 1: 70%|███████ | 70/100 [00:35<00:14, 2.06 epochs/s, Training Loss=3.05e-5, Validation Loss=3.05e-5, Best Loss=2.51e-5]
Training Fold 1: 70%|███████ | 70/100 [00:35<00:14, 2.06 epochs/s, Training Loss=2.72e-5, Validation Loss=2.62e-5, Best Loss=2.51e-5]
Training Fold 1: 71%|███████ | 71/100 [00:35<00:14, 2.06 epochs/s, Training Loss=2.72e-5, Validation Loss=2.62e-5, Best Loss=2.51e-5]
Training Fold 1: 71%|███████ | 71/100 [00:36<00:14, 2.06 epochs/s, Training Loss=2.53e-5, Validation Loss=2.51e-5, Best Loss=2.51e-5]
Training Fold 1: 72%|███████▏ | 72/100 [00:36<00:13, 2.05 epochs/s, Training Loss=2.53e-5, Validation Loss=2.51e-5, Best Loss=2.51e-5]
Training Fold 1: 72%|███████▏ | 72/100 [00:36<00:13, 2.05 epochs/s, Training Loss=2.57e-5, Validation Loss=2.62e-5, Best Loss=2.51e-5]
Training Fold 1: 73%|███████▎ | 73/100 [00:36<00:13, 2.04 epochs/s, Training Loss=2.57e-5, Validation Loss=2.62e-5, Best Loss=2.51e-5]
Training Fold 1: 73%|███████▎ | 73/100 [00:37<00:13, 2.04 epochs/s, Training Loss=2.76e-5, Validation Loss=2.65e-5, Best Loss=2.51e-5]
Training Fold 1: 74%|███████▍ | 74/100 [00:37<00:12, 2.08 epochs/s, Training Loss=2.76e-5, Validation Loss=2.65e-5, Best Loss=2.51e-5]
Training Fold 1: 74%|███████▍ | 74/100 [00:37<00:12, 2.08 epochs/s, Training Loss=2.59e-5, Validation Loss=2.3e-5, Best Loss=2.3e-5]
Training Fold 1: 75%|███████▌ | 75/100 [00:37<00:12, 2.07 epochs/s, Training Loss=2.59e-5, Validation Loss=2.3e-5, Best Loss=2.3e-5]
Training Fold 1: 75%|███████▌ | 75/100 [00:38<00:12, 2.07 epochs/s, Training Loss=2.36e-5, Validation Loss=2.39e-5, Best Loss=2.3e-5]
Training Fold 1: 76%|███████▌ | 76/100 [00:38<00:11, 2.09 epochs/s, Training Loss=2.36e-5, Validation Loss=2.39e-5, Best Loss=2.3e-5]
Training Fold 1: 76%|███████▌ | 76/100 [00:38<00:11, 2.09 epochs/s, Training Loss=2.76e-5, Validation Loss=2.63e-5, Best Loss=2.3e-5]
Training Fold 1: 77%|███████▋ | 77/100 [00:38<00:10, 2.11 epochs/s, Training Loss=2.76e-5, Validation Loss=2.63e-5, Best Loss=2.3e-5]
Training Fold 1: 77%|███████▋ | 77/100 [00:39<00:10, 2.11 epochs/s, Training Loss=2.54e-5, Validation Loss=2.36e-5, Best Loss=2.3e-5]
Training Fold 1: 78%|███████▊ | 78/100 [00:39<00:10, 2.10 epochs/s, Training Loss=2.54e-5, Validation Loss=2.36e-5, Best Loss=2.3e-5]
Training Fold 1: 78%|███████▊ | 78/100 [00:39<00:10, 2.10 epochs/s, Training Loss=2.26e-5, Validation Loss=2.28e-5, Best Loss=2.28e-5]
Training Fold 1: 79%|███████▉ | 79/100 [00:39<00:10, 2.08 epochs/s, Training Loss=2.26e-5, Validation Loss=2.28e-5, Best Loss=2.28e-5]
Training Fold 1: 79%|███████▉ | 79/100 [00:40<00:10, 2.08 epochs/s, Training Loss=2.44e-5, Validation Loss=2.15e-5, Best Loss=2.15e-5]
Training Fold 1: 80%|████████ | 80/100 [00:40<00:09, 2.08 epochs/s, Training Loss=2.44e-5, Validation Loss=2.15e-5, Best Loss=2.15e-5]
Training Fold 1: 80%|████████ | 80/100 [00:40<00:09, 2.08 epochs/s, Training Loss=2.26e-5, Validation Loss=2.15e-5, Best Loss=2.15e-5]
Training Fold 1: 81%|████████ | 81/100 [00:40<00:09, 1.97 epochs/s, Training Loss=2.26e-5, Validation Loss=2.15e-5, Best Loss=2.15e-5]
Training Fold 1: 81%|████████ | 81/100 [00:41<00:09, 1.97 epochs/s, Training Loss=2.74e-5, Validation Loss=2.88e-5, Best Loss=2.15e-5]
Training Fold 1: 82%|████████▏ | 82/100 [00:41<00:09, 1.98 epochs/s, Training Loss=2.74e-5, Validation Loss=2.88e-5, Best Loss=2.15e-5]
Training Fold 1: 82%|████████▏ | 82/100 [00:41<00:09, 1.98 epochs/s, Training Loss=2.28e-5, Validation Loss=2.35e-5, Best Loss=2.15e-5]
Training Fold 1: 83%|████████▎ | 83/100 [00:41<00:08, 1.99 epochs/s, Training Loss=2.28e-5, Validation Loss=2.35e-5, Best Loss=2.15e-5]
Training Fold 1: 83%|████████▎ | 83/100 [00:42<00:08, 1.99 epochs/s, Training Loss=2.06e-5, Validation Loss=1.93e-5, Best Loss=1.93e-5]
Training Fold 1: 84%|████████▍ | 84/100 [00:42<00:07, 2.03 epochs/s, Training Loss=2.06e-5, Validation Loss=1.93e-5, Best Loss=1.93e-5]
Training Fold 1: 84%|████████▍ | 84/100 [00:42<00:07, 2.03 epochs/s, Training Loss=2.07e-5, Validation Loss=1.94e-5, Best Loss=1.93e-5]
Training Fold 1: 85%|████████▌ | 85/100 [00:42<00:07, 2.02 epochs/s, Training Loss=2.07e-5, Validation Loss=1.94e-5, Best Loss=1.93e-5]
Training Fold 1: 85%|████████▌ | 85/100 [00:43<00:07, 2.02 epochs/s, Training Loss=2.19e-5, Validation Loss=2.16e-5, Best Loss=1.93e-5]
Training Fold 1: 86%|████████▌ | 86/100 [00:43<00:06, 2.06 epochs/s, Training Loss=2.19e-5, Validation Loss=2.16e-5, Best Loss=1.93e-5]
Training Fold 1: 86%|████████▌ | 86/100 [00:43<00:06, 2.06 epochs/s, Training Loss=2.37e-5, Validation Loss=2.44e-5, Best Loss=1.93e-5]
Training Fold 1: 87%|████████▋ | 87/100 [00:43<00:06, 2.05 epochs/s, Training Loss=2.37e-5, Validation Loss=2.44e-5, Best Loss=1.93e-5]
Training Fold 1: 87%|████████▋ | 87/100 [00:44<00:06, 2.05 epochs/s, Training Loss=2.58e-5, Validation Loss=2.8e-5, Best Loss=1.93e-5]
Training Fold 1: 88%|████████▊ | 88/100 [00:44<00:05, 2.07 epochs/s, Training Loss=2.58e-5, Validation Loss=2.8e-5, Best Loss=1.93e-5]
Training Fold 1: 88%|████████▊ | 88/100 [00:44<00:05, 2.07 epochs/s, Training Loss=2.07e-5, Validation Loss=2.09e-5, Best Loss=1.93e-5]
Training Fold 1: 89%|████████▉ | 89/100 [00:44<00:05, 2.08 epochs/s, Training Loss=2.07e-5, Validation Loss=2.09e-5, Best Loss=1.93e-5]
Training Fold 1: 89%|████████▉ | 89/100 [00:45<00:05, 2.08 epochs/s, Training Loss=2.07e-5, Validation Loss=1.96e-5, Best Loss=1.93e-5]
Training Fold 1: 90%|█████████ | 90/100 [00:45<00:04, 2.07 epochs/s, Training Loss=2.07e-5, Validation Loss=1.96e-5, Best Loss=1.93e-5]
Training Fold 1: 90%|█████████ | 90/100 [00:45<00:04, 2.07 epochs/s, Training Loss=2.43e-5, Validation Loss=2.56e-5, Best Loss=1.93e-5]
Training Fold 1: 91%|█████████ | 91/100 [00:45<00:04, 2.08 epochs/s, Training Loss=2.43e-5, Validation Loss=2.56e-5, Best Loss=1.93e-5]
Training Fold 1: 91%|█████████ | 91/100 [00:46<00:04, 2.08 epochs/s, Training Loss=2.16e-5, Validation Loss=2.26e-5, Best Loss=1.93e-5]
Training Fold 1: 92%|█████████▏| 92/100 [00:46<00:03, 2.08 epochs/s, Training Loss=2.16e-5, Validation Loss=2.26e-5, Best Loss=1.93e-5]
Training Fold 1: 92%|█████████▏| 92/100 [00:46<00:03, 2.08 epochs/s, Training Loss=2.09e-5, Validation Loss=2.18e-5, Best Loss=1.93e-5]
Training Fold 1: 93%|█████████▎| 93/100 [00:46<00:03, 2.07 epochs/s, Training Loss=2.09e-5, Validation Loss=2.18e-5, Best Loss=1.93e-5]
Training Fold 1: 93%|█████████▎| 93/100 [00:47<00:03, 2.07 epochs/s, Training Loss=2.08e-5, Validation Loss=2.17e-5, Best Loss=1.93e-5]
Training Fold 1: 94%|█████████▍| 94/100 [00:47<00:02, 2.07 epochs/s, Training Loss=2.08e-5, Validation Loss=2.17e-5, Best Loss=1.93e-5]
Training Fold 1: 94%|█████████▍| 94/100 [00:47<00:02, 2.07 epochs/s, Training Loss=2.54e-5, Validation Loss=2.4e-5, Best Loss=1.93e-5]
Training Fold 1: 95%|█████████▌| 95/100 [00:47<00:02, 2.05 epochs/s, Training Loss=2.54e-5, Validation Loss=2.4e-5, Best Loss=1.93e-5]
Training Fold 1: 95%|█████████▌| 95/100 [00:47<00:02, 2.05 epochs/s, Training Loss=2.13e-5, Validation Loss=2.03e-5, Best Loss=1.93e-5]
Training Fold 1: 96%|█████████▌| 96/100 [00:47<00:01, 2.09 epochs/s, Training Loss=2.13e-5, Validation Loss=2.03e-5, Best Loss=1.93e-5]
Training Fold 1: 96%|█████████▌| 96/100 [00:48<00:01, 2.09 epochs/s, Training Loss=2.11e-5, Validation Loss=2.11e-5, Best Loss=1.93e-5]
Training Fold 1: 97%|█████████▋| 97/100 [00:48<00:01, 2.09 epochs/s, Training Loss=2.11e-5, Validation Loss=2.11e-5, Best Loss=1.93e-5]
Training Fold 1: 97%|█████████▋| 97/100 [00:48<00:01, 2.09 epochs/s, Training Loss=1.94e-5, Validation Loss=1.88e-5, Best Loss=1.88e-5]
Training Fold 1: 98%|█████████▊| 98/100 [00:48<00:00, 2.08 epochs/s, Training Loss=1.94e-5, Validation Loss=1.88e-5, Best Loss=1.88e-5]
Training Fold 1: 98%|█████████▊| 98/100 [00:49<00:00, 2.08 epochs/s, Training Loss=2.19e-5, Validation Loss=1.85e-5, Best Loss=1.85e-5]
Training Fold 1: 99%|█████████▉| 99/100 [00:49<00:00, 2.10 epochs/s, Training Loss=2.19e-5, Validation Loss=1.85e-5, Best Loss=1.85e-5]
Training Fold 1: 99%|█████████▉| 99/100 [00:49<00:00, 2.10 epochs/s, Training Loss=1.94e-5, Validation Loss=2.06e-5, Best Loss=1.85e-5]
Training Fold 1: 100%|██████████| 100/100 [00:49<00:00, 2.11 epochs/s, Training Loss=1.94e-5, Validation Loss=2.06e-5, Best Loss=1.85e-5]
Training Fold 1: 100%|██████████| 100/100 [00:49<00:00, 2.01 epochs/s, Training Loss=1.94e-5, Validation Loss=2.06e-5, Best Loss=1.85e-5]
0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 2: 0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 2: 0%| | 0/100 [00:00<?, ? epochs/s, Training Loss=3.02e-5, Validation Loss=2.37e-5, Best Loss=1.85e-5]
Training Fold 2: 1%| | 1/100 [00:00<00:44, 2.25 epochs/s, Training Loss=3.02e-5, Validation Loss=2.37e-5, Best Loss=1.85e-5]
Training Fold 2: 1%| | 1/100 [00:00<00:44, 2.25 epochs/s, Training Loss=2.8e-5, Validation Loss=2.42e-5, Best Loss=1.85e-5]
Training Fold 2: 2%|▏ | 2/100 [00:00<00:45, 2.18 epochs/s, Training Loss=2.8e-5, Validation Loss=2.42e-5, Best Loss=1.85e-5]
Training Fold 2: 2%|▏ | 2/100 [00:01<00:45, 2.18 epochs/s, Training Loss=2.11e-5, Validation Loss=1.77e-5, Best Loss=1.77e-5]
Training Fold 2: 3%|▎ | 3/100 [00:01<00:44, 2.19 epochs/s, Training Loss=2.11e-5, Validation Loss=1.77e-5, Best Loss=1.77e-5]
Training Fold 2: 3%|▎ | 3/100 [00:01<00:44, 2.19 epochs/s, Training Loss=2.06e-5, Validation Loss=1.67e-5, Best Loss=1.67e-5]
Training Fold 2: 4%|▍ | 4/100 [00:01<00:44, 2.17 epochs/s, Training Loss=2.06e-5, Validation Loss=1.67e-5, Best Loss=1.67e-5]
Training Fold 2: 4%|▍ | 4/100 [00:02<00:44, 2.17 epochs/s, Training Loss=2.63e-5, Validation Loss=2.22e-5, Best Loss=1.67e-5]
Training Fold 2: 5%|▌ | 5/100 [00:02<00:44, 2.15 epochs/s, Training Loss=2.63e-5, Validation Loss=2.22e-5, Best Loss=1.67e-5]
Training Fold 2: 5%|▌ | 5/100 [00:02<00:44, 2.15 epochs/s, Training Loss=2.33e-5, Validation Loss=2.09e-5, Best Loss=1.67e-5]
Training Fold 2: 6%|▌ | 6/100 [00:02<00:44, 2.09 epochs/s, Training Loss=2.33e-5, Validation Loss=2.09e-5, Best Loss=1.67e-5]
Training Fold 2: 6%|▌ | 6/100 [00:03<00:44, 2.09 epochs/s, Training Loss=1.93e-5, Validation Loss=1.54e-5, Best Loss=1.54e-5]
Training Fold 2: 7%|▋ | 7/100 [00:03<00:44, 2.11 epochs/s, Training Loss=1.93e-5, Validation Loss=1.54e-5, Best Loss=1.54e-5]
Training Fold 2: 7%|▋ | 7/100 [00:03<00:44, 2.11 epochs/s, Training Loss=1.87e-5, Validation Loss=1.54e-5, Best Loss=1.54e-5]
Training Fold 2: 8%|▊ | 8/100 [00:03<00:44, 2.08 epochs/s, Training Loss=1.87e-5, Validation Loss=1.54e-5, Best Loss=1.54e-5]
Training Fold 2: 8%|▊ | 8/100 [00:04<00:44, 2.08 epochs/s, Training Loss=2.12e-5, Validation Loss=1.93e-5, Best Loss=1.54e-5]
Training Fold 2: 9%|▉ | 9/100 [00:04<00:44, 2.04 epochs/s, Training Loss=2.12e-5, Validation Loss=1.93e-5, Best Loss=1.54e-5]
Training Fold 2: 9%|▉ | 9/100 [00:04<00:44, 2.04 epochs/s, Training Loss=1.81e-5, Validation Loss=1.53e-5, Best Loss=1.53e-5]
Training Fold 2: 10%|█ | 10/100 [00:04<00:44, 2.03 epochs/s, Training Loss=1.81e-5, Validation Loss=1.53e-5, Best Loss=1.53e-5]
Training Fold 2: 10%|█ | 10/100 [00:05<00:44, 2.03 epochs/s, Training Loss=2.04e-5, Validation Loss=1.78e-5, Best Loss=1.53e-5]
Training Fold 2: 11%|█ | 11/100 [00:05<00:42, 2.07 epochs/s, Training Loss=2.04e-5, Validation Loss=1.78e-5, Best Loss=1.53e-5]
Training Fold 2: 11%|█ | 11/100 [00:05<00:42, 2.07 epochs/s, Training Loss=1.82e-5, Validation Loss=1.56e-5, Best Loss=1.53e-5]
Training Fold 2: 12%|█▏ | 12/100 [00:05<00:43, 2.03 epochs/s, Training Loss=1.82e-5, Validation Loss=1.56e-5, Best Loss=1.53e-5]
Training Fold 2: 12%|█▏ | 12/100 [00:06<00:43, 2.03 epochs/s, Training Loss=1.87e-5, Validation Loss=1.64e-5, Best Loss=1.53e-5]
Training Fold 2: 13%|█▎ | 13/100 [00:06<00:42, 2.03 epochs/s, Training Loss=1.87e-5, Validation Loss=1.64e-5, Best Loss=1.53e-5]
Training Fold 2: 13%|█▎ | 13/100 [00:06<00:42, 2.03 epochs/s, Training Loss=2.53e-5, Validation Loss=2.12e-5, Best Loss=1.53e-5]
Training Fold 2: 14%|█▍ | 14/100 [00:06<00:41, 2.08 epochs/s, Training Loss=2.53e-5, Validation Loss=2.12e-5, Best Loss=1.53e-5]
Training Fold 2: 14%|█▍ | 14/100 [00:07<00:41, 2.08 epochs/s, Training Loss=1.87e-5, Validation Loss=1.61e-5, Best Loss=1.53e-5]
Training Fold 2: 15%|█▌ | 15/100 [00:07<00:41, 2.03 epochs/s, Training Loss=1.87e-5, Validation Loss=1.61e-5, Best Loss=1.53e-5]
Training Fold 2: 15%|█▌ | 15/100 [00:07<00:41, 2.03 epochs/s, Training Loss=1.84e-5, Validation Loss=1.63e-5, Best Loss=1.53e-5]
Training Fold 2: 16%|█▌ | 16/100 [00:07<00:41, 2.03 epochs/s, Training Loss=1.84e-5, Validation Loss=1.63e-5, Best Loss=1.53e-5]
Training Fold 2: 16%|█▌ | 16/100 [00:08<00:41, 2.03 epochs/s, Training Loss=2.1e-5, Validation Loss=1.89e-5, Best Loss=1.53e-5]
Training Fold 2: 17%|█▋ | 17/100 [00:08<00:40, 2.07 epochs/s, Training Loss=2.1e-5, Validation Loss=1.89e-5, Best Loss=1.53e-5]
Training Fold 2: 17%|█▋ | 17/100 [00:08<00:40, 2.07 epochs/s, Training Loss=1.83e-5, Validation Loss=1.68e-5, Best Loss=1.53e-5]
Training Fold 2: 18%|█▊ | 18/100 [00:08<00:40, 2.04 epochs/s, Training Loss=1.83e-5, Validation Loss=1.68e-5, Best Loss=1.53e-5]
Training Fold 2: 18%|█▊ | 18/100 [00:09<00:40, 2.04 epochs/s, Training Loss=1.85e-5, Validation Loss=1.61e-5, Best Loss=1.53e-5]
Training Fold 2: 19%|█▉ | 19/100 [00:09<00:39, 2.04 epochs/s, Training Loss=1.85e-5, Validation Loss=1.61e-5, Best Loss=1.53e-5]
Training Fold 2: 19%|█▉ | 19/100 [00:09<00:39, 2.04 epochs/s, Training Loss=1.79e-5, Validation Loss=1.64e-5, Best Loss=1.53e-5]
Training Fold 2: 20%|██ | 20/100 [00:09<00:39, 2.01 epochs/s, Training Loss=1.79e-5, Validation Loss=1.64e-5, Best Loss=1.53e-5]
Training Fold 2: 20%|██ | 20/100 [00:10<00:39, 2.01 epochs/s, Training Loss=1.96e-5, Validation Loss=1.85e-5, Best Loss=1.53e-5]
Training Fold 2: 21%|██ | 21/100 [00:10<00:39, 2.02 epochs/s, Training Loss=1.96e-5, Validation Loss=1.85e-5, Best Loss=1.53e-5]
Training Fold 2: 21%|██ | 21/100 [00:10<00:39, 2.02 epochs/s, Training Loss=2.01e-5, Validation Loss=1.75e-5, Best Loss=1.53e-5]
Training Fold 2: 22%|██▏ | 22/100 [00:10<00:37, 2.05 epochs/s, Training Loss=2.01e-5, Validation Loss=1.75e-5, Best Loss=1.53e-5]
Training Fold 2: 22%|██▏ | 22/100 [00:11<00:37, 2.05 epochs/s, Training Loss=1.85e-5, Validation Loss=1.65e-5, Best Loss=1.53e-5]
Training Fold 2: 23%|██▎ | 23/100 [00:11<00:36, 2.10 epochs/s, Training Loss=1.85e-5, Validation Loss=1.65e-5, Best Loss=1.53e-5]
Training Fold 2: 23%|██▎ | 23/100 [00:11<00:36, 2.10 epochs/s, Training Loss=1.84e-5, Validation Loss=1.65e-5, Best Loss=1.53e-5]
Training Fold 2: 24%|██▍ | 24/100 [00:11<00:36, 2.09 epochs/s, Training Loss=1.84e-5, Validation Loss=1.65e-5, Best Loss=1.53e-5]
Training Fold 2: 24%|██▍ | 24/100 [00:12<00:36, 2.09 epochs/s, Training Loss=1.67e-5, Validation Loss=1.52e-5, Best Loss=1.52e-5]
Training Fold 2: 25%|██▌ | 25/100 [00:12<00:35, 2.11 epochs/s, Training Loss=1.67e-5, Validation Loss=1.52e-5, Best Loss=1.52e-5]
Training Fold 2: 25%|██▌ | 25/100 [00:12<00:35, 2.11 epochs/s, Training Loss=1.79e-5, Validation Loss=1.77e-5, Best Loss=1.52e-5]
Training Fold 2: 26%|██▌ | 26/100 [00:12<00:35, 2.09 epochs/s, Training Loss=1.79e-5, Validation Loss=1.77e-5, Best Loss=1.52e-5]
Training Fold 2: 26%|██▌ | 26/100 [00:12<00:35, 2.09 epochs/s, Training Loss=1.76e-5, Validation Loss=1.54e-5, Best Loss=1.52e-5]
Training Fold 2: 27%|██▋ | 27/100 [00:12<00:34, 2.12 epochs/s, Training Loss=1.76e-5, Validation Loss=1.54e-5, Best Loss=1.52e-5]
Training Fold 2: 27%|██▋ | 27/100 [00:13<00:34, 2.12 epochs/s, Training Loss=1.68e-5, Validation Loss=1.47e-5, Best Loss=1.47e-5]
Training Fold 2: 28%|██▊ | 28/100 [00:13<00:34, 2.12 epochs/s, Training Loss=1.68e-5, Validation Loss=1.47e-5, Best Loss=1.47e-5]
Training Fold 2: 28%|██▊ | 28/100 [00:14<00:34, 2.12 epochs/s, Training Loss=2.1e-5, Validation Loss=2.17e-5, Best Loss=1.47e-5]
Training Fold 2: 29%|██▉ | 29/100 [00:14<00:35, 2.03 epochs/s, Training Loss=2.1e-5, Validation Loss=2.17e-5, Best Loss=1.47e-5]
Training Fold 2: 29%|██▉ | 29/100 [00:14<00:35, 2.03 epochs/s, Training Loss=1.88e-5, Validation Loss=1.7e-5, Best Loss=1.47e-5]
Training Fold 2: 30%|███ | 30/100 [00:14<00:35, 1.98 epochs/s, Training Loss=1.88e-5, Validation Loss=1.7e-5, Best Loss=1.47e-5]
Training Fold 2: 30%|███ | 30/100 [00:15<00:35, 1.98 epochs/s, Training Loss=1.98e-5, Validation Loss=1.91e-5, Best Loss=1.47e-5]
Training Fold 2: 31%|███ | 31/100 [00:15<00:34, 1.97 epochs/s, Training Loss=1.98e-5, Validation Loss=1.91e-5, Best Loss=1.47e-5]
Training Fold 2: 31%|███ | 31/100 [00:15<00:34, 1.97 epochs/s, Training Loss=1.71e-5, Validation Loss=1.59e-5, Best Loss=1.47e-5]
Training Fold 2: 32%|███▏ | 32/100 [00:15<00:34, 1.98 epochs/s, Training Loss=1.71e-5, Validation Loss=1.59e-5, Best Loss=1.47e-5]
Training Fold 2: 32%|███▏ | 32/100 [00:16<00:34, 1.98 epochs/s, Training Loss=1.68e-5, Validation Loss=1.56e-5, Best Loss=1.47e-5]
Training Fold 2: 33%|███▎ | 33/100 [00:16<00:33, 2.00 epochs/s, Training Loss=1.68e-5, Validation Loss=1.56e-5, Best Loss=1.47e-5]
Training Fold 2: 33%|███▎ | 33/100 [00:16<00:33, 2.00 epochs/s, Training Loss=1.72e-5, Validation Loss=1.57e-5, Best Loss=1.47e-5]
Training Fold 2: 34%|███▍ | 34/100 [00:16<00:32, 2.01 epochs/s, Training Loss=1.72e-5, Validation Loss=1.57e-5, Best Loss=1.47e-5]
Training Fold 2: 34%|███▍ | 34/100 [00:16<00:32, 2.01 epochs/s, Training Loss=1.79e-5, Validation Loss=1.68e-5, Best Loss=1.47e-5]
Training Fold 2: 35%|███▌ | 35/100 [00:16<00:31, 2.05 epochs/s, Training Loss=1.79e-5, Validation Loss=1.68e-5, Best Loss=1.47e-5]
Training Fold 2: 35%|███▌ | 35/100 [00:17<00:31, 2.05 epochs/s, Training Loss=1.75e-5, Validation Loss=1.63e-5, Best Loss=1.47e-5]
Training Fold 2: 36%|███▌ | 36/100 [00:17<00:30, 2.07 epochs/s, Training Loss=1.75e-5, Validation Loss=1.63e-5, Best Loss=1.47e-5]
Training Fold 2: 36%|███▌ | 36/100 [00:17<00:30, 2.07 epochs/s, Training Loss=1.91e-5, Validation Loss=1.84e-5, Best Loss=1.47e-5]
Training Fold 2: 37%|███▋ | 37/100 [00:17<00:31, 2.01 epochs/s, Training Loss=1.91e-5, Validation Loss=1.84e-5, Best Loss=1.47e-5]
Training Fold 2: 37%|███▋ | 37/100 [00:18<00:31, 2.01 epochs/s, Training Loss=1.55e-5, Validation Loss=1.48e-5, Best Loss=1.47e-5]
Training Fold 2: 38%|███▊ | 38/100 [00:18<00:31, 1.98 epochs/s, Training Loss=1.55e-5, Validation Loss=1.48e-5, Best Loss=1.47e-5]
Training Fold 2: 38%|███▊ | 38/100 [00:19<00:31, 1.98 epochs/s, Training Loss=1.59e-5, Validation Loss=1.5e-5, Best Loss=1.47e-5]
Training Fold 2: 39%|███▉ | 39/100 [00:19<00:30, 1.99 epochs/s, Training Loss=1.59e-5, Validation Loss=1.5e-5, Best Loss=1.47e-5]
Training Fold 2: 39%|███▉ | 39/100 [00:19<00:30, 1.99 epochs/s, Training Loss=1.78e-5, Validation Loss=1.62e-5, Best Loss=1.47e-5]
Training Fold 2: 40%|████ | 40/100 [00:19<00:30, 1.98 epochs/s, Training Loss=1.78e-5, Validation Loss=1.62e-5, Best Loss=1.47e-5]
Training Fold 2: 40%|████ | 40/100 [00:19<00:30, 1.98 epochs/s, Training Loss=1.6e-5, Validation Loss=1.52e-5, Best Loss=1.47e-5]
Training Fold 2: 41%|████ | 41/100 [00:19<00:28, 2.04 epochs/s, Training Loss=1.6e-5, Validation Loss=1.52e-5, Best Loss=1.47e-5]
Training Fold 2: 41%|████ | 41/100 [00:20<00:28, 2.04 epochs/s, Training Loss=1.7e-5, Validation Loss=1.6e-5, Best Loss=1.47e-5]
Training Fold 2: 42%|████▏ | 42/100 [00:20<00:28, 2.05 epochs/s, Training Loss=1.7e-5, Validation Loss=1.6e-5, Best Loss=1.47e-5]
Training Fold 2: 42%|████▏ | 42/100 [00:20<00:28, 2.05 epochs/s, Training Loss=2.05e-5, Validation Loss=2.03e-5, Best Loss=1.47e-5]
Training Fold 2: 43%|████▎ | 43/100 [00:20<00:27, 2.07 epochs/s, Training Loss=2.05e-5, Validation Loss=2.03e-5, Best Loss=1.47e-5]
Training Fold 2: 43%|████▎ | 43/100 [00:21<00:27, 2.07 epochs/s, Training Loss=4.19e-5, Validation Loss=4.14e-5, Best Loss=1.47e-5]
Training Fold 2: 44%|████▍ | 44/100 [00:21<00:26, 2.10 epochs/s, Training Loss=4.19e-5, Validation Loss=4.14e-5, Best Loss=1.47e-5]
Training Fold 2: 44%|████▍ | 44/100 [00:21<00:26, 2.10 epochs/s, Training Loss=1.59e-5, Validation Loss=1.58e-5, Best Loss=1.47e-5]
Training Fold 2: 45%|████▌ | 45/100 [00:21<00:25, 2.12 epochs/s, Training Loss=1.59e-5, Validation Loss=1.58e-5, Best Loss=1.47e-5]
Training Fold 2: 45%|████▌ | 45/100 [00:22<00:25, 2.12 epochs/s, Training Loss=1.54e-5, Validation Loss=1.49e-5, Best Loss=1.47e-5]
Training Fold 2: 46%|████▌ | 46/100 [00:22<00:25, 2.12 epochs/s, Training Loss=1.54e-5, Validation Loss=1.49e-5, Best Loss=1.47e-5]
Training Fold 2: 46%|████▌ | 46/100 [00:22<00:25, 2.12 epochs/s, Training Loss=1.55e-5, Validation Loss=1.46e-5, Best Loss=1.46e-5]
Training Fold 2: 47%|████▋ | 47/100 [00:22<00:25, 2.04 epochs/s, Training Loss=1.55e-5, Validation Loss=1.46e-5, Best Loss=1.46e-5]
Training Fold 2: 47%|████▋ | 47/100 [00:23<00:25, 2.04 epochs/s, Training Loss=1.67e-5, Validation Loss=1.67e-5, Best Loss=1.46e-5]
Training Fold 2: 48%|████▊ | 48/100 [00:23<00:25, 2.03 epochs/s, Training Loss=1.67e-5, Validation Loss=1.67e-5, Best Loss=1.46e-5]
Training Fold 2: 48%|████▊ | 48/100 [00:23<00:25, 2.03 epochs/s, Training Loss=1.58e-5, Validation Loss=1.52e-5, Best Loss=1.46e-5]
Training Fold 2: 49%|████▉ | 49/100 [00:23<00:25, 2.02 epochs/s, Training Loss=1.58e-5, Validation Loss=1.52e-5, Best Loss=1.46e-5]
Training Fold 2: 49%|████▉ | 49/100 [00:24<00:25, 2.02 epochs/s, Training Loss=1.55e-5, Validation Loss=1.55e-5, Best Loss=1.46e-5]
Training Fold 2: 50%|█████ | 50/100 [00:24<00:24, 2.02 epochs/s, Training Loss=1.55e-5, Validation Loss=1.55e-5, Best Loss=1.46e-5]
Training Fold 2: 50%|█████ | 50/100 [00:24<00:24, 2.02 epochs/s, Training Loss=1.56e-5, Validation Loss=1.61e-5, Best Loss=1.46e-5]
Training Fold 2: 51%|█████ | 51/100 [00:24<00:24, 2.01 epochs/s, Training Loss=1.56e-5, Validation Loss=1.61e-5, Best Loss=1.46e-5]
Training Fold 2: 51%|█████ | 51/100 [00:25<00:24, 2.01 epochs/s, Training Loss=1.77e-5, Validation Loss=1.8e-5, Best Loss=1.46e-5]
Training Fold 2: 52%|█████▏ | 52/100 [00:25<00:23, 2.04 epochs/s, Training Loss=1.77e-5, Validation Loss=1.8e-5, Best Loss=1.46e-5]
Training Fold 2: 52%|█████▏ | 52/100 [00:25<00:23, 2.04 epochs/s, Training Loss=1.55e-5, Validation Loss=1.62e-5, Best Loss=1.46e-5]
Training Fold 2: 53%|█████▎ | 53/100 [00:25<00:23, 1.99 epochs/s, Training Loss=1.55e-5, Validation Loss=1.62e-5, Best Loss=1.46e-5]
Training Fold 2: 53%|█████▎ | 53/100 [00:26<00:23, 1.99 epochs/s, Training Loss=1.63e-5, Validation Loss=1.67e-5, Best Loss=1.46e-5]
Training Fold 2: 54%|█████▍ | 54/100 [00:26<00:22, 2.01 epochs/s, Training Loss=1.63e-5, Validation Loss=1.67e-5, Best Loss=1.46e-5]
Training Fold 2: 54%|█████▍ | 54/100 [00:26<00:22, 2.01 epochs/s, Training Loss=1.59e-5, Validation Loss=1.6e-5, Best Loss=1.46e-5]
Training Fold 2: 55%|█████▌ | 55/100 [00:26<00:22, 2.05 epochs/s, Training Loss=1.59e-5, Validation Loss=1.6e-5, Best Loss=1.46e-5]
Training Fold 2: 55%|█████▌ | 55/100 [00:27<00:22, 2.05 epochs/s, Training Loss=1.6e-5, Validation Loss=1.66e-5, Best Loss=1.46e-5]
Training Fold 2: 56%|█████▌ | 56/100 [00:27<00:21, 2.07 epochs/s, Training Loss=1.6e-5, Validation Loss=1.66e-5, Best Loss=1.46e-5]
Training Fold 2: 56%|█████▌ | 56/100 [00:27<00:21, 2.07 epochs/s, Training Loss=1.47e-5, Validation Loss=1.49e-5, Best Loss=1.46e-5]
Training Fold 2: 57%|█████▋ | 57/100 [00:27<00:20, 2.05 epochs/s, Training Loss=1.47e-5, Validation Loss=1.49e-5, Best Loss=1.46e-5]
Training Fold 2: 57%|█████▋ | 57/100 [00:28<00:20, 2.05 epochs/s, Training Loss=1.69e-5, Validation Loss=1.86e-5, Best Loss=1.46e-5]
Training Fold 2: 58%|█████▊ | 58/100 [00:28<00:20, 2.06 epochs/s, Training Loss=1.69e-5, Validation Loss=1.86e-5, Best Loss=1.46e-5]
Training Fold 2: 58%|█████▊ | 58/100 [00:28<00:20, 2.06 epochs/s, Training Loss=1.68e-5, Validation Loss=1.77e-5, Best Loss=1.46e-5]
Training Fold 2: 59%|█████▉ | 59/100 [00:28<00:19, 2.05 epochs/s, Training Loss=1.68e-5, Validation Loss=1.77e-5, Best Loss=1.46e-5]
Training Fold 2: 59%|█████▉ | 59/100 [00:29<00:19, 2.05 epochs/s, Training Loss=1.45e-5, Validation Loss=1.52e-5, Best Loss=1.46e-5]
Training Fold 2: 60%|██████ | 60/100 [00:29<00:19, 2.07 epochs/s, Training Loss=1.45e-5, Validation Loss=1.52e-5, Best Loss=1.46e-5]
Training Fold 2: 60%|██████ | 60/100 [00:29<00:19, 2.07 epochs/s, Training Loss=1.61e-5, Validation Loss=1.7e-5, Best Loss=1.46e-5]
Training Fold 2: 61%|██████ | 61/100 [00:29<00:18, 2.07 epochs/s, Training Loss=1.61e-5, Validation Loss=1.7e-5, Best Loss=1.46e-5]
Training Fold 2: 61%|██████ | 61/100 [00:30<00:18, 2.07 epochs/s, Training Loss=1.56e-5, Validation Loss=1.61e-5, Best Loss=1.46e-5]
Training Fold 2: 62%|██████▏ | 62/100 [00:30<00:18, 2.07 epochs/s, Training Loss=1.56e-5, Validation Loss=1.61e-5, Best Loss=1.46e-5]
Training Fold 2: 62%|██████▏ | 62/100 [00:30<00:18, 2.07 epochs/s, Training Loss=1.47e-5, Validation Loss=1.5e-5, Best Loss=1.46e-5]
Training Fold 2: 63%|██████▎ | 63/100 [00:30<00:17, 2.06 epochs/s, Training Loss=1.47e-5, Validation Loss=1.5e-5, Best Loss=1.46e-5]
Training Fold 2: 63%|██████▎ | 63/100 [00:31<00:17, 2.06 epochs/s, Training Loss=1.44e-5, Validation Loss=1.53e-5, Best Loss=1.46e-5]
Training Fold 2: 64%|██████▍ | 64/100 [00:31<00:17, 2.05 epochs/s, Training Loss=1.44e-5, Validation Loss=1.53e-5, Best Loss=1.46e-5]
Training Fold 2: 64%|██████▍ | 64/100 [00:31<00:17, 2.05 epochs/s, Training Loss=1.46e-5, Validation Loss=1.51e-5, Best Loss=1.46e-5]
Training Fold 2: 65%|██████▌ | 65/100 [00:31<00:16, 2.09 epochs/s, Training Loss=1.46e-5, Validation Loss=1.51e-5, Best Loss=1.46e-5]
Training Fold 2: 65%|██████▌ | 65/100 [00:32<00:16, 2.09 epochs/s, Training Loss=1.49e-5, Validation Loss=1.52e-5, Best Loss=1.46e-5]
Training Fold 2: 66%|██████▌ | 66/100 [00:32<00:16, 2.05 epochs/s, Training Loss=1.49e-5, Validation Loss=1.52e-5, Best Loss=1.46e-5]
Training Fold 2: 66%|██████▌ | 66/100 [00:32<00:16, 2.05 epochs/s, Training Loss=1.99e-5, Validation Loss=1.83e-5, Best Loss=1.46e-5]
Training Fold 2: 67%|██████▋ | 67/100 [00:32<00:16, 2.05 epochs/s, Training Loss=1.99e-5, Validation Loss=1.83e-5, Best Loss=1.46e-5]
Training Fold 2: 67%|██████▋ | 67/100 [00:33<00:16, 2.05 epochs/s, Training Loss=1.55e-5, Validation Loss=1.51e-5, Best Loss=1.46e-5]
Training Fold 2: 68%|██████▊ | 68/100 [00:33<00:15, 2.07 epochs/s, Training Loss=1.55e-5, Validation Loss=1.51e-5, Best Loss=1.46e-5]
Training Fold 2: 68%|██████▊ | 68/100 [00:33<00:15, 2.07 epochs/s, Training Loss=1.49e-5, Validation Loss=1.56e-5, Best Loss=1.46e-5]
Training Fold 2: 69%|██████▉ | 69/100 [00:33<00:15, 2.00 epochs/s, Training Loss=1.49e-5, Validation Loss=1.56e-5, Best Loss=1.46e-5]
Training Fold 2: 69%|██████▉ | 69/100 [00:34<00:15, 2.00 epochs/s, Training Loss=1.42e-5, Validation Loss=1.42e-5, Best Loss=1.42e-5]
Training Fold 2: 70%|███████ | 70/100 [00:34<00:14, 2.01 epochs/s, Training Loss=1.42e-5, Validation Loss=1.42e-5, Best Loss=1.42e-5]
Training Fold 2: 70%|███████ | 70/100 [00:34<00:14, 2.01 epochs/s, Training Loss=1.61e-5, Validation Loss=1.7e-5, Best Loss=1.42e-5]
Training Fold 2: 71%|███████ | 71/100 [00:34<00:14, 2.00 epochs/s, Training Loss=1.61e-5, Validation Loss=1.7e-5, Best Loss=1.42e-5]
Training Fold 2: 71%|███████ | 71/100 [00:35<00:14, 2.00 epochs/s, Training Loss=1.51e-5, Validation Loss=1.5e-5, Best Loss=1.42e-5]
Training Fold 2: 72%|███████▏ | 72/100 [00:35<00:14, 1.99 epochs/s, Training Loss=1.51e-5, Validation Loss=1.5e-5, Best Loss=1.42e-5]
Training Fold 2: 72%|███████▏ | 72/100 [00:35<00:14, 1.99 epochs/s, Training Loss=1.47e-5, Validation Loss=1.42e-5, Best Loss=1.42e-5]
Training Fold 2: 73%|███████▎ | 73/100 [00:35<00:13, 1.97 epochs/s, Training Loss=1.47e-5, Validation Loss=1.42e-5, Best Loss=1.42e-5]
Training Fold 2: 73%|███████▎ | 73/100 [00:36<00:13, 1.97 epochs/s, Training Loss=1.39e-5, Validation Loss=1.41e-5, Best Loss=1.41e-5]
Training Fold 2: 74%|███████▍ | 74/100 [00:36<00:13, 1.97 epochs/s, Training Loss=1.39e-5, Validation Loss=1.41e-5, Best Loss=1.41e-5]
Training Fold 2: 74%|███████▍ | 74/100 [00:36<00:13, 1.97 epochs/s, Training Loss=2.03e-5, Validation Loss=2.13e-5, Best Loss=1.41e-5]
Training Fold 2: 75%|███████▌ | 75/100 [00:36<00:13, 1.89 epochs/s, Training Loss=2.03e-5, Validation Loss=2.13e-5, Best Loss=1.41e-5]
Training Fold 2: 75%|███████▌ | 75/100 [00:37<00:13, 1.89 epochs/s, Training Loss=1.62e-5, Validation Loss=1.69e-5, Best Loss=1.41e-5]
Training Fold 2: 76%|███████▌ | 76/100 [00:37<00:12, 1.89 epochs/s, Training Loss=1.62e-5, Validation Loss=1.69e-5, Best Loss=1.41e-5]
Training Fold 2: 76%|███████▌ | 76/100 [00:37<00:12, 1.89 epochs/s, Training Loss=1.61e-5, Validation Loss=1.79e-5, Best Loss=1.41e-5]
Training Fold 2: 77%|███████▋ | 77/100 [00:37<00:11, 1.92 epochs/s, Training Loss=1.61e-5, Validation Loss=1.79e-5, Best Loss=1.41e-5]
Training Fold 2: 77%|███████▋ | 77/100 [00:38<00:11, 1.92 epochs/s, Training Loss=1.5e-5, Validation Loss=1.67e-5, Best Loss=1.41e-5]
Training Fold 2: 78%|███████▊ | 78/100 [00:38<00:11, 1.92 epochs/s, Training Loss=1.5e-5, Validation Loss=1.67e-5, Best Loss=1.41e-5]
Training Fold 2: 78%|███████▊ | 78/100 [00:38<00:11, 1.92 epochs/s, Training Loss=1.48e-5, Validation Loss=1.61e-5, Best Loss=1.41e-5]
Training Fold 2: 79%|███████▉ | 79/100 [00:38<00:10, 1.94 epochs/s, Training Loss=1.48e-5, Validation Loss=1.61e-5, Best Loss=1.41e-5]
Training Fold 2: 79%|███████▉ | 79/100 [00:39<00:10, 1.94 epochs/s, Training Loss=2.05e-5, Validation Loss=2.24e-5, Best Loss=1.41e-5]
Training Fold 2: 80%|████████ | 80/100 [00:39<00:10, 1.96 epochs/s, Training Loss=2.05e-5, Validation Loss=2.24e-5, Best Loss=1.41e-5]
Training Fold 2: 80%|████████ | 80/100 [00:39<00:10, 1.96 epochs/s, Training Loss=1.44e-5, Validation Loss=1.55e-5, Best Loss=1.41e-5]
Training Fold 2: 81%|████████ | 81/100 [00:39<00:09, 1.97 epochs/s, Training Loss=1.44e-5, Validation Loss=1.55e-5, Best Loss=1.41e-5]
Training Fold 2: 81%|████████ | 81/100 [00:40<00:09, 1.97 epochs/s, Training Loss=1.39e-5, Validation Loss=1.47e-5, Best Loss=1.41e-5]
Training Fold 2: 82%|████████▏ | 82/100 [00:40<00:09, 2.00 epochs/s, Training Loss=1.39e-5, Validation Loss=1.47e-5, Best Loss=1.41e-5]
Training Fold 2: 82%|████████▏ | 82/100 [00:40<00:09, 2.00 epochs/s, Training Loss=1.87e-5, Validation Loss=2.34e-5, Best Loss=1.41e-5]
Training Fold 2: 83%|████████▎ | 83/100 [00:40<00:08, 2.00 epochs/s, Training Loss=1.87e-5, Validation Loss=2.34e-5, Best Loss=1.41e-5]
Training Fold 2: 83%|████████▎ | 83/100 [00:41<00:08, 2.00 epochs/s, Training Loss=1.4e-5, Validation Loss=1.49e-5, Best Loss=1.41e-5]
Training Fold 2: 84%|████████▍ | 84/100 [00:41<00:07, 2.01 epochs/s, Training Loss=1.4e-5, Validation Loss=1.49e-5, Best Loss=1.41e-5]
Training Fold 2: 84%|████████▍ | 84/100 [00:41<00:07, 2.01 epochs/s, Training Loss=1.41e-5, Validation Loss=1.57e-5, Best Loss=1.41e-5]
Training Fold 2: 85%|████████▌ | 85/100 [00:41<00:07, 2.03 epochs/s, Training Loss=1.41e-5, Validation Loss=1.57e-5, Best Loss=1.41e-5]
Training Fold 2: 85%|████████▌ | 85/100 [00:42<00:07, 2.03 epochs/s, Training Loss=1.39e-5, Validation Loss=1.45e-5, Best Loss=1.41e-5]
Training Fold 2: 86%|████████▌ | 86/100 [00:42<00:06, 2.03 epochs/s, Training Loss=1.39e-5, Validation Loss=1.45e-5, Best Loss=1.41e-5]
Training Fold 2: 86%|████████▌ | 86/100 [00:42<00:06, 2.03 epochs/s, Training Loss=1.34e-5, Validation Loss=1.42e-5, Best Loss=1.41e-5]
Training Fold 2: 87%|████████▋ | 87/100 [00:42<00:06, 2.01 epochs/s, Training Loss=1.34e-5, Validation Loss=1.42e-5, Best Loss=1.41e-5]
Training Fold 2: 87%|████████▋ | 87/100 [00:43<00:06, 2.01 epochs/s, Training Loss=1.47e-5, Validation Loss=1.69e-5, Best Loss=1.41e-5]
Training Fold 2: 88%|████████▊ | 88/100 [00:43<00:05, 2.06 epochs/s, Training Loss=1.47e-5, Validation Loss=1.69e-5, Best Loss=1.41e-5]
Training Fold 2: 88%|████████▊ | 88/100 [00:43<00:05, 2.06 epochs/s, Training Loss=1.76e-5, Validation Loss=1.98e-5, Best Loss=1.41e-5]
Training Fold 2: 89%|████████▉ | 89/100 [00:43<00:05, 2.05 epochs/s, Training Loss=1.76e-5, Validation Loss=1.98e-5, Best Loss=1.41e-5]
Training Fold 2: 89%|████████▉ | 89/100 [00:44<00:05, 2.05 epochs/s, Training Loss=1.39e-5, Validation Loss=1.46e-5, Best Loss=1.41e-5]
Training Fold 2: 90%|█████████ | 90/100 [00:44<00:04, 2.06 epochs/s, Training Loss=1.39e-5, Validation Loss=1.46e-5, Best Loss=1.41e-5]
Training Fold 2: 90%|█████████ | 90/100 [00:44<00:04, 2.06 epochs/s, Training Loss=1.69e-5, Validation Loss=1.89e-5, Best Loss=1.41e-5]
Training Fold 2: 91%|█████████ | 91/100 [00:44<00:04, 2.08 epochs/s, Training Loss=1.69e-5, Validation Loss=1.89e-5, Best Loss=1.41e-5]
Training Fold 2: 91%|█████████ | 91/100 [00:45<00:04, 2.08 epochs/s, Training Loss=1.34e-5, Validation Loss=1.43e-5, Best Loss=1.41e-5]
Training Fold 2: 92%|█████████▏| 92/100 [00:45<00:03, 2.09 epochs/s, Training Loss=1.34e-5, Validation Loss=1.43e-5, Best Loss=1.41e-5]
Training Fold 2: 92%|█████████▏| 92/100 [00:45<00:03, 2.09 epochs/s, Training Loss=1.4e-5, Validation Loss=1.51e-5, Best Loss=1.41e-5]
Training Fold 2: 93%|█████████▎| 93/100 [00:45<00:03, 2.07 epochs/s, Training Loss=1.4e-5, Validation Loss=1.51e-5, Best Loss=1.41e-5]
Training Fold 2: 93%|█████████▎| 93/100 [00:46<00:03, 2.07 epochs/s, Training Loss=1.43e-5, Validation Loss=1.53e-5, Best Loss=1.41e-5]
Training Fold 2: 94%|█████████▍| 94/100 [00:46<00:02, 2.09 epochs/s, Training Loss=1.43e-5, Validation Loss=1.53e-5, Best Loss=1.41e-5]
Training Fold 2: 94%|█████████▍| 94/100 [00:46<00:02, 2.09 epochs/s, Training Loss=1.38e-5, Validation Loss=1.54e-5, Best Loss=1.41e-5]
Training Fold 2: 95%|█████████▌| 95/100 [00:46<00:02, 2.07 epochs/s, Training Loss=1.38e-5, Validation Loss=1.54e-5, Best Loss=1.41e-5]
Training Fold 2: 95%|█████████▌| 95/100 [00:47<00:02, 2.07 epochs/s, Training Loss=1.52e-5, Validation Loss=1.62e-5, Best Loss=1.41e-5]
Training Fold 2: 96%|█████████▌| 96/100 [00:47<00:01, 2.05 epochs/s, Training Loss=1.52e-5, Validation Loss=1.62e-5, Best Loss=1.41e-5]
Training Fold 2: 96%|█████████▌| 96/100 [00:47<00:01, 2.05 epochs/s, Training Loss=1.32e-5, Validation Loss=1.47e-5, Best Loss=1.41e-5]
Training Fold 2: 97%|█████████▋| 97/100 [00:47<00:01, 2.10 epochs/s, Training Loss=1.32e-5, Validation Loss=1.47e-5, Best Loss=1.41e-5]
Training Fold 2: 97%|█████████▋| 97/100 [00:48<00:01, 2.10 epochs/s, Training Loss=1.43e-5, Validation Loss=1.47e-5, Best Loss=1.41e-5]
Training Fold 2: 98%|█████████▊| 98/100 [00:48<00:00, 2.11 epochs/s, Training Loss=1.43e-5, Validation Loss=1.47e-5, Best Loss=1.41e-5]
Training Fold 2: 98%|█████████▊| 98/100 [00:48<00:00, 2.11 epochs/s, Training Loss=1.3e-5, Validation Loss=1.51e-5, Best Loss=1.41e-5]
Training Fold 2: 99%|█████████▉| 99/100 [00:48<00:00, 2.10 epochs/s, Training Loss=1.3e-5, Validation Loss=1.51e-5, Best Loss=1.41e-5]
Training Fold 2: 99%|█████████▉| 99/100 [00:49<00:00, 2.10 epochs/s, Training Loss=1.37e-5, Validation Loss=1.54e-5, Best Loss=1.41e-5]
Training Fold 2: 100%|██████████| 100/100 [00:49<00:00, 2.05 epochs/s, Training Loss=1.37e-5, Validation Loss=1.54e-5, Best Loss=1.41e-5]
Training Fold 2: 100%|██████████| 100/100 [00:49<00:00, 2.04 epochs/s, Training Loss=1.37e-5, Validation Loss=1.54e-5, Best Loss=1.41e-5]
0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 3: 0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 3: 0%| | 0/100 [00:00<?, ? epochs/s, Training Loss=1.42e-5, Validation Loss=1.1e-5, Best Loss=1.1e-5]
Training Fold 3: 1%| | 1/100 [00:00<00:46, 2.15 epochs/s, Training Loss=1.42e-5, Validation Loss=1.1e-5, Best Loss=1.1e-5]
Training Fold 3: 1%| | 1/100 [00:00<00:46, 2.15 epochs/s, Training Loss=1.5e-5, Validation Loss=1.17e-5, Best Loss=1.1e-5]
Training Fold 3: 2%|▏ | 2/100 [00:00<00:45, 2.17 epochs/s, Training Loss=1.5e-5, Validation Loss=1.17e-5, Best Loss=1.1e-5]
Training Fold 3: 2%|▏ | 2/100 [00:01<00:45, 2.17 epochs/s, Training Loss=1.49e-5, Validation Loss=1.16e-5, Best Loss=1.1e-5]
Training Fold 3: 3%|▎ | 3/100 [00:01<00:44, 2.16 epochs/s, Training Loss=1.49e-5, Validation Loss=1.16e-5, Best Loss=1.1e-5]
Training Fold 3: 3%|▎ | 3/100 [00:01<00:44, 2.16 epochs/s, Training Loss=1.36e-5, Validation Loss=1.01e-5, Best Loss=1.01e-5]
Training Fold 3: 4%|▍ | 4/100 [00:01<00:45, 2.12 epochs/s, Training Loss=1.36e-5, Validation Loss=1.01e-5, Best Loss=1.01e-5]
Training Fold 3: 4%|▍ | 4/100 [00:02<00:45, 2.12 epochs/s, Training Loss=1.4e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 3: 5%|▌ | 5/100 [00:02<00:44, 2.14 epochs/s, Training Loss=1.4e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 3: 5%|▌ | 5/100 [00:02<00:44, 2.14 epochs/s, Training Loss=1.44e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 6%|▌ | 6/100 [00:02<00:47, 1.99 epochs/s, Training Loss=1.44e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 6%|▌ | 6/100 [00:03<00:47, 1.99 epochs/s, Training Loss=1.56e-5, Validation Loss=1.38e-5, Best Loss=1.01e-5]
Training Fold 3: 7%|▋ | 7/100 [00:03<00:48, 1.94 epochs/s, Training Loss=1.56e-5, Validation Loss=1.38e-5, Best Loss=1.01e-5]
Training Fold 3: 7%|▋ | 7/100 [00:03<00:48, 1.94 epochs/s, Training Loss=1.58e-5, Validation Loss=1.37e-5, Best Loss=1.01e-5]
Training Fold 3: 8%|▊ | 8/100 [00:03<00:47, 1.93 epochs/s, Training Loss=1.58e-5, Validation Loss=1.37e-5, Best Loss=1.01e-5]
Training Fold 3: 8%|▊ | 8/100 [00:04<00:47, 1.93 epochs/s, Training Loss=1.44e-5, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 3: 9%|▉ | 9/100 [00:04<00:49, 1.85 epochs/s, Training Loss=1.44e-5, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 3: 9%|▉ | 9/100 [00:05<00:49, 1.85 epochs/s, Training Loss=1.33e-5, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 3: 10%|█ | 10/100 [00:05<00:47, 1.88 epochs/s, Training Loss=1.33e-5, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 3: 10%|█ | 10/100 [00:05<00:47, 1.88 epochs/s, Training Loss=1.53e-5, Validation Loss=1.36e-5, Best Loss=1.01e-5]
Training Fold 3: 11%|█ | 11/100 [00:05<00:46, 1.93 epochs/s, Training Loss=1.53e-5, Validation Loss=1.36e-5, Best Loss=1.01e-5]
Training Fold 3: 11%|█ | 11/100 [00:06<00:46, 1.93 epochs/s, Training Loss=2.35e-5, Validation Loss=2.19e-5, Best Loss=1.01e-5]
Training Fold 3: 12%|█▏ | 12/100 [00:06<00:44, 1.97 epochs/s, Training Loss=2.35e-5, Validation Loss=2.19e-5, Best Loss=1.01e-5]
Training Fold 3: 12%|█▏ | 12/100 [00:06<00:44, 1.97 epochs/s, Training Loss=2.2e-5, Validation Loss=2.32e-5, Best Loss=1.01e-5]
Training Fold 3: 13%|█▎ | 13/100 [00:06<00:43, 2.00 epochs/s, Training Loss=2.2e-5, Validation Loss=2.32e-5, Best Loss=1.01e-5]
Training Fold 3: 13%|█▎ | 13/100 [00:06<00:43, 2.00 epochs/s, Training Loss=1.36e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 14%|█▍ | 14/100 [00:06<00:42, 2.03 epochs/s, Training Loss=1.36e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 14%|█▍ | 14/100 [00:07<00:42, 2.03 epochs/s, Training Loss=1.34e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 3: 15%|█▌ | 15/100 [00:07<00:41, 2.05 epochs/s, Training Loss=1.34e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 3: 15%|█▌ | 15/100 [00:08<00:41, 2.05 epochs/s, Training Loss=1.38e-5, Validation Loss=1.31e-5, Best Loss=1.01e-5]
Training Fold 3: 16%|█▌ | 16/100 [00:08<00:42, 1.99 epochs/s, Training Loss=1.38e-5, Validation Loss=1.31e-5, Best Loss=1.01e-5]
Training Fold 3: 16%|█▌ | 16/100 [00:08<00:42, 1.99 epochs/s, Training Loss=1.43e-5, Validation Loss=1.43e-5, Best Loss=1.01e-5]
Training Fold 3: 17%|█▋ | 17/100 [00:08<00:41, 2.01 epochs/s, Training Loss=1.43e-5, Validation Loss=1.43e-5, Best Loss=1.01e-5]
Training Fold 3: 17%|█▋ | 17/100 [00:08<00:41, 2.01 epochs/s, Training Loss=1.44e-5, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 3: 18%|█▊ | 18/100 [00:08<00:40, 2.02 epochs/s, Training Loss=1.44e-5, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 3: 18%|█▊ | 18/100 [00:09<00:40, 2.02 epochs/s, Training Loss=1.41e-5, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 3: 19%|█▉ | 19/100 [00:09<00:39, 2.04 epochs/s, Training Loss=1.41e-5, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 3: 19%|█▉ | 19/100 [00:09<00:39, 2.04 epochs/s, Training Loss=1.36e-5, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 3: 20%|██ | 20/100 [00:09<00:40, 2.00 epochs/s, Training Loss=1.36e-5, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 3: 20%|██ | 20/100 [00:10<00:40, 2.00 epochs/s, Training Loss=1.64e-5, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 3: 21%|██ | 21/100 [00:10<00:39, 2.03 epochs/s, Training Loss=1.64e-5, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 3: 21%|██ | 21/100 [00:10<00:39, 2.03 epochs/s, Training Loss=1.3e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 22%|██▏ | 22/100 [00:10<00:38, 2.03 epochs/s, Training Loss=1.3e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 22%|██▏ | 22/100 [00:11<00:38, 2.03 epochs/s, Training Loss=1.72e-5, Validation Loss=1.67e-5, Best Loss=1.01e-5]
Training Fold 3: 23%|██▎ | 23/100 [00:11<00:38, 2.02 epochs/s, Training Loss=1.72e-5, Validation Loss=1.67e-5, Best Loss=1.01e-5]
Training Fold 3: 23%|██▎ | 23/100 [00:11<00:38, 2.02 epochs/s, Training Loss=1.41e-5, Validation Loss=1.35e-5, Best Loss=1.01e-5]
Training Fold 3: 24%|██▍ | 24/100 [00:11<00:37, 2.04 epochs/s, Training Loss=1.41e-5, Validation Loss=1.35e-5, Best Loss=1.01e-5]
Training Fold 3: 24%|██▍ | 24/100 [00:12<00:37, 2.04 epochs/s, Training Loss=1.49e-5, Validation Loss=1.31e-5, Best Loss=1.01e-5]
Training Fold 3: 25%|██▌ | 25/100 [00:12<00:36, 2.07 epochs/s, Training Loss=1.49e-5, Validation Loss=1.31e-5, Best Loss=1.01e-5]
Training Fold 3: 25%|██▌ | 25/100 [00:12<00:36, 2.07 epochs/s, Training Loss=1.37e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 26%|██▌ | 26/100 [00:12<00:36, 2.04 epochs/s, Training Loss=1.37e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 26%|██▌ | 26/100 [00:13<00:36, 2.04 epochs/s, Training Loss=1.5e-5, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 3: 27%|██▋ | 27/100 [00:13<00:36, 2.02 epochs/s, Training Loss=1.5e-5, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 3: 27%|██▋ | 27/100 [00:13<00:36, 2.02 epochs/s, Training Loss=1.32e-5, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 3: 28%|██▊ | 28/100 [00:13<00:35, 2.04 epochs/s, Training Loss=1.32e-5, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 3: 28%|██▊ | 28/100 [00:14<00:35, 2.04 epochs/s, Training Loss=1.75e-5, Validation Loss=1.74e-5, Best Loss=1.01e-5]
Training Fold 3: 29%|██▉ | 29/100 [00:14<00:35, 2.00 epochs/s, Training Loss=1.75e-5, Validation Loss=1.74e-5, Best Loss=1.01e-5]
Training Fold 3: 29%|██▉ | 29/100 [00:14<00:35, 2.00 epochs/s, Training Loss=1.31e-5, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 3: 30%|███ | 30/100 [00:14<00:34, 2.06 epochs/s, Training Loss=1.31e-5, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 3: 30%|███ | 30/100 [00:15<00:34, 2.06 epochs/s, Training Loss=1.22e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 31%|███ | 31/100 [00:15<00:33, 2.07 epochs/s, Training Loss=1.22e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 31%|███ | 31/100 [00:15<00:33, 2.07 epochs/s, Training Loss=1.26e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 32%|███▏ | 32/100 [00:15<00:33, 2.03 epochs/s, Training Loss=1.26e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 32%|███▏ | 32/100 [00:16<00:33, 2.03 epochs/s, Training Loss=2.07e-5, Validation Loss=2.22e-5, Best Loss=1.01e-5]
Training Fold 3: 33%|███▎ | 33/100 [00:16<00:33, 2.01 epochs/s, Training Loss=2.07e-5, Validation Loss=2.22e-5, Best Loss=1.01e-5]
Training Fold 3: 33%|███▎ | 33/100 [00:16<00:33, 2.01 epochs/s, Training Loss=3.14e-5, Validation Loss=2.82e-5, Best Loss=1.01e-5]
Training Fold 3: 34%|███▍ | 34/100 [00:16<00:32, 2.03 epochs/s, Training Loss=3.14e-5, Validation Loss=2.82e-5, Best Loss=1.01e-5]
Training Fold 3: 34%|███▍ | 34/100 [00:17<00:32, 2.03 epochs/s, Training Loss=1.48e-5, Validation Loss=1.47e-5, Best Loss=1.01e-5]
Training Fold 3: 35%|███▌ | 35/100 [00:17<00:31, 2.06 epochs/s, Training Loss=1.48e-5, Validation Loss=1.47e-5, Best Loss=1.01e-5]
Training Fold 3: 35%|███▌ | 35/100 [00:17<00:31, 2.06 epochs/s, Training Loss=1.34e-5, Validation Loss=1.33e-5, Best Loss=1.01e-5]
Training Fold 3: 36%|███▌ | 36/100 [00:17<00:31, 2.04 epochs/s, Training Loss=1.34e-5, Validation Loss=1.33e-5, Best Loss=1.01e-5]
Training Fold 3: 36%|███▌ | 36/100 [00:18<00:31, 2.04 epochs/s, Training Loss=1.45e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 37%|███▋ | 37/100 [00:18<00:30, 2.06 epochs/s, Training Loss=1.45e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 37%|███▋ | 37/100 [00:18<00:30, 2.06 epochs/s, Training Loss=1.26e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 38%|███▊ | 38/100 [00:18<00:30, 2.03 epochs/s, Training Loss=1.26e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 38%|███▊ | 38/100 [00:19<00:30, 2.03 epochs/s, Training Loss=1.3e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 39%|███▉ | 39/100 [00:19<00:30, 2.03 epochs/s, Training Loss=1.3e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 39%|███▉ | 39/100 [00:19<00:30, 2.03 epochs/s, Training Loss=1.47e-5, Validation Loss=1.6e-5, Best Loss=1.01e-5]
Training Fold 3: 40%|████ | 40/100 [00:19<00:29, 2.04 epochs/s, Training Loss=1.47e-5, Validation Loss=1.6e-5, Best Loss=1.01e-5]
Training Fold 3: 40%|████ | 40/100 [00:20<00:29, 2.04 epochs/s, Training Loss=1.51e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 41%|████ | 41/100 [00:20<00:29, 2.03 epochs/s, Training Loss=1.51e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 41%|████ | 41/100 [00:20<00:29, 2.03 epochs/s, Training Loss=1.38e-5, Validation Loss=1.44e-5, Best Loss=1.01e-5]
Training Fold 3: 42%|████▏ | 42/100 [00:20<00:29, 1.98 epochs/s, Training Loss=1.38e-5, Validation Loss=1.44e-5, Best Loss=1.01e-5]
Training Fold 3: 42%|████▏ | 42/100 [00:21<00:29, 1.98 epochs/s, Training Loss=1.46e-5, Validation Loss=1.33e-5, Best Loss=1.01e-5]
Training Fold 3: 43%|████▎ | 43/100 [00:21<00:28, 2.02 epochs/s, Training Loss=1.46e-5, Validation Loss=1.33e-5, Best Loss=1.01e-5]
Training Fold 3: 43%|████▎ | 43/100 [00:21<00:28, 2.02 epochs/s, Training Loss=1.32e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 44%|████▍ | 44/100 [00:21<00:27, 2.02 epochs/s, Training Loss=1.32e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 44%|████▍ | 44/100 [00:22<00:27, 2.02 epochs/s, Training Loss=1.37e-5, Validation Loss=1.38e-5, Best Loss=1.01e-5]
Training Fold 3: 45%|████▌ | 45/100 [00:22<00:27, 2.03 epochs/s, Training Loss=1.37e-5, Validation Loss=1.38e-5, Best Loss=1.01e-5]
Training Fold 3: 45%|████▌ | 45/100 [00:22<00:27, 2.03 epochs/s, Training Loss=1.43e-5, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 3: 46%|████▌ | 46/100 [00:22<00:28, 1.92 epochs/s, Training Loss=1.43e-5, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 3: 46%|████▌ | 46/100 [00:23<00:28, 1.92 epochs/s, Training Loss=1.3e-5, Validation Loss=1.27e-5, Best Loss=1.01e-5]
Training Fold 3: 47%|████▋ | 47/100 [00:23<00:27, 1.92 epochs/s, Training Loss=1.3e-5, Validation Loss=1.27e-5, Best Loss=1.01e-5]
Training Fold 3: 47%|████▋ | 47/100 [00:23<00:27, 1.92 epochs/s, Training Loss=1.29e-5, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 3: 48%|████▊ | 48/100 [00:23<00:27, 1.92 epochs/s, Training Loss=1.29e-5, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 3: 48%|████▊ | 48/100 [00:24<00:27, 1.92 epochs/s, Training Loss=1.35e-5, Validation Loss=1.32e-5, Best Loss=1.01e-5]
Training Fold 3: 49%|████▉ | 49/100 [00:24<00:26, 1.93 epochs/s, Training Loss=1.35e-5, Validation Loss=1.32e-5, Best Loss=1.01e-5]
Training Fold 3: 49%|████▉ | 49/100 [00:24<00:26, 1.93 epochs/s, Training Loss=1.27e-5, Validation Loss=1.38e-5, Best Loss=1.01e-5]
Training Fold 3: 50%|█████ | 50/100 [00:24<00:25, 1.93 epochs/s, Training Loss=1.27e-5, Validation Loss=1.38e-5, Best Loss=1.01e-5]
Training Fold 3: 50%|█████ | 50/100 [00:25<00:25, 1.93 epochs/s, Training Loss=1.2e-5, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 3: 51%|█████ | 51/100 [00:25<00:25, 1.89 epochs/s, Training Loss=1.2e-5, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 3: 51%|█████ | 51/100 [00:25<00:25, 1.89 epochs/s, Training Loss=1.35e-5, Validation Loss=1.26e-5, Best Loss=1.01e-5]
Training Fold 3: 52%|█████▏ | 52/100 [00:25<00:24, 1.94 epochs/s, Training Loss=1.35e-5, Validation Loss=1.26e-5, Best Loss=1.01e-5]
Training Fold 3: 52%|█████▏ | 52/100 [00:26<00:24, 1.94 epochs/s, Training Loss=1.29e-5, Validation Loss=1.4e-5, Best Loss=1.01e-5]
Training Fold 3: 53%|█████▎ | 53/100 [00:26<00:23, 1.97 epochs/s, Training Loss=1.29e-5, Validation Loss=1.4e-5, Best Loss=1.01e-5]
Training Fold 3: 53%|█████▎ | 53/100 [00:26<00:23, 1.97 epochs/s, Training Loss=1.61e-5, Validation Loss=1.71e-5, Best Loss=1.01e-5]
Training Fold 3: 54%|█████▍ | 54/100 [00:26<00:23, 1.94 epochs/s, Training Loss=1.61e-5, Validation Loss=1.71e-5, Best Loss=1.01e-5]
Training Fold 3: 54%|█████▍ | 54/100 [00:27<00:23, 1.94 epochs/s, Training Loss=1.33e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 3: 55%|█████▌ | 55/100 [00:27<00:22, 2.00 epochs/s, Training Loss=1.33e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 3: 55%|█████▌ | 55/100 [00:27<00:22, 2.00 epochs/s, Training Loss=2.01e-5, Validation Loss=1.62e-5, Best Loss=1.01e-5]
Training Fold 3: 56%|█████▌ | 56/100 [00:27<00:21, 2.00 epochs/s, Training Loss=2.01e-5, Validation Loss=1.62e-5, Best Loss=1.01e-5]
Training Fold 3: 56%|█████▌ | 56/100 [00:28<00:21, 2.00 epochs/s, Training Loss=1.38e-5, Validation Loss=1.37e-5, Best Loss=1.01e-5]
Training Fold 3: 57%|█████▋ | 57/100 [00:28<00:21, 2.02 epochs/s, Training Loss=1.38e-5, Validation Loss=1.37e-5, Best Loss=1.01e-5]
Training Fold 3: 57%|█████▋ | 57/100 [00:28<00:21, 2.02 epochs/s, Training Loss=1.19e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 58%|█████▊ | 58/100 [00:28<00:20, 2.01 epochs/s, Training Loss=1.19e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 58%|█████▊ | 58/100 [00:29<00:20, 2.01 epochs/s, Training Loss=1.38e-5, Validation Loss=1.56e-5, Best Loss=1.01e-5]
Training Fold 3: 59%|█████▉ | 59/100 [00:29<00:20, 2.03 epochs/s, Training Loss=1.38e-5, Validation Loss=1.56e-5, Best Loss=1.01e-5]
Training Fold 3: 59%|█████▉ | 59/100 [00:29<00:20, 2.03 epochs/s, Training Loss=1.11e-5, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 3: 60%|██████ | 60/100 [00:29<00:19, 2.03 epochs/s, Training Loss=1.11e-5, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 3: 60%|██████ | 60/100 [00:30<00:19, 2.03 epochs/s, Training Loss=1.27e-5, Validation Loss=1.36e-5, Best Loss=1.01e-5]
Training Fold 3: 61%|██████ | 61/100 [00:30<00:18, 2.05 epochs/s, Training Loss=1.27e-5, Validation Loss=1.36e-5, Best Loss=1.01e-5]
Training Fold 3: 61%|██████ | 61/100 [00:30<00:18, 2.05 epochs/s, Training Loss=1.35e-5, Validation Loss=1.24e-5, Best Loss=1.01e-5]
Training Fold 3: 62%|██████▏ | 62/100 [00:30<00:18, 2.07 epochs/s, Training Loss=1.35e-5, Validation Loss=1.24e-5, Best Loss=1.01e-5]
Training Fold 3: 62%|██████▏ | 62/100 [00:31<00:18, 2.07 epochs/s, Training Loss=1.4e-5, Validation Loss=1.47e-5, Best Loss=1.01e-5]
Training Fold 3: 63%|██████▎ | 63/100 [00:31<00:17, 2.06 epochs/s, Training Loss=1.4e-5, Validation Loss=1.47e-5, Best Loss=1.01e-5]
Training Fold 3: 63%|██████▎ | 63/100 [00:31<00:17, 2.06 epochs/s, Training Loss=1.23e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 64%|██████▍ | 64/100 [00:31<00:17, 2.05 epochs/s, Training Loss=1.23e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 64%|██████▍ | 64/100 [00:32<00:17, 2.05 epochs/s, Training Loss=1.23e-5, Validation Loss=1.4e-5, Best Loss=1.01e-5]
Training Fold 3: 65%|██████▌ | 65/100 [00:32<00:17, 2.03 epochs/s, Training Loss=1.23e-5, Validation Loss=1.4e-5, Best Loss=1.01e-5]
Training Fold 3: 65%|██████▌ | 65/100 [00:32<00:17, 2.03 epochs/s, Training Loss=1.23e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 66%|██████▌ | 66/100 [00:32<00:17, 2.00 epochs/s, Training Loss=1.23e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 66%|██████▌ | 66/100 [00:33<00:17, 2.00 epochs/s, Training Loss=1.15e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 67%|██████▋ | 67/100 [00:33<00:16, 2.00 epochs/s, Training Loss=1.15e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 67%|██████▋ | 67/100 [00:33<00:16, 2.00 epochs/s, Training Loss=1.11e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 68%|██████▊ | 68/100 [00:33<00:15, 2.01 epochs/s, Training Loss=1.11e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 68%|██████▊ | 68/100 [00:34<00:15, 2.01 epochs/s, Training Loss=1.27e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 69%|██████▉ | 69/100 [00:34<00:15, 2.06 epochs/s, Training Loss=1.27e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 3: 69%|██████▉ | 69/100 [00:34<00:15, 2.06 epochs/s, Training Loss=1.11e-5, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 3: 70%|███████ | 70/100 [00:34<00:14, 2.05 epochs/s, Training Loss=1.11e-5, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 3: 70%|███████ | 70/100 [00:35<00:14, 2.05 epochs/s, Training Loss=1.1e-5, Validation Loss=1.02e-5, Best Loss=1.01e-5]
Training Fold 3: 71%|███████ | 71/100 [00:35<00:14, 2.03 epochs/s, Training Loss=1.1e-5, Validation Loss=1.02e-5, Best Loss=1.01e-5]
Training Fold 3: 71%|███████ | 71/100 [00:35<00:14, 2.03 epochs/s, Training Loss=1.13e-5, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 3: 72%|███████▏ | 72/100 [00:35<00:13, 2.02 epochs/s, Training Loss=1.13e-5, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 3: 72%|███████▏ | 72/100 [00:36<00:13, 2.02 epochs/s, Training Loss=1.06e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 3: 73%|███████▎ | 73/100 [00:36<00:13, 2.04 epochs/s, Training Loss=1.06e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 3: 73%|███████▎ | 73/100 [00:36<00:13, 2.04 epochs/s, Training Loss=2.94e-5, Validation Loss=3.03e-5, Best Loss=1.01e-5]
Training Fold 3: 74%|███████▍ | 74/100 [00:36<00:12, 2.00 epochs/s, Training Loss=2.94e-5, Validation Loss=3.03e-5, Best Loss=1.01e-5]
Training Fold 3: 74%|███████▍ | 74/100 [00:37<00:12, 2.00 epochs/s, Training Loss=1.13e-5, Validation Loss=1.23e-5, Best Loss=1.01e-5]
Training Fold 3: 75%|███████▌ | 75/100 [00:37<00:12, 1.99 epochs/s, Training Loss=1.13e-5, Validation Loss=1.23e-5, Best Loss=1.01e-5]
Training Fold 3: 75%|███████▌ | 75/100 [00:37<00:12, 1.99 epochs/s, Training Loss=1.1e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 76%|███████▌ | 76/100 [00:37<00:11, 2.01 epochs/s, Training Loss=1.1e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 76%|███████▌ | 76/100 [00:38<00:11, 2.01 epochs/s, Training Loss=1.15e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 77%|███████▋ | 77/100 [00:38<00:11, 1.99 epochs/s, Training Loss=1.15e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 77%|███████▋ | 77/100 [00:38<00:11, 1.99 epochs/s, Training Loss=1.12e-5, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 3: 78%|███████▊ | 78/100 [00:38<00:10, 2.01 epochs/s, Training Loss=1.12e-5, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 3: 78%|███████▊ | 78/100 [00:39<00:10, 2.01 epochs/s, Training Loss=1.05e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 79%|███████▉ | 79/100 [00:39<00:10, 2.02 epochs/s, Training Loss=1.05e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 79%|███████▉ | 79/100 [00:39<00:10, 2.02 epochs/s, Training Loss=1.16e-5, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 3: 80%|████████ | 80/100 [00:39<00:09, 2.03 epochs/s, Training Loss=1.16e-5, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 3: 80%|████████ | 80/100 [00:40<00:09, 2.03 epochs/s, Training Loss=1.15e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 81%|████████ | 81/100 [00:40<00:09, 2.04 epochs/s, Training Loss=1.15e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 3: 81%|████████ | 81/100 [00:40<00:09, 2.04 epochs/s, Training Loss=1.15e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 82%|████████▏ | 82/100 [00:40<00:09, 1.96 epochs/s, Training Loss=1.15e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 82%|████████▏ | 82/100 [00:41<00:09, 1.96 epochs/s, Training Loss=1.02e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 83%|████████▎ | 83/100 [00:41<00:08, 1.95 epochs/s, Training Loss=1.02e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 3: 83%|████████▎ | 83/100 [00:41<00:08, 1.95 epochs/s, Training Loss=1.2e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 84%|████████▍ | 84/100 [00:41<00:08, 1.97 epochs/s, Training Loss=1.2e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 84%|████████▍ | 84/100 [00:42<00:08, 1.97 epochs/s, Training Loss=1.3e-5, Validation Loss=1.37e-5, Best Loss=1.01e-5]
Training Fold 3: 85%|████████▌ | 85/100 [00:42<00:07, 1.98 epochs/s, Training Loss=1.3e-5, Validation Loss=1.37e-5, Best Loss=1.01e-5]
Training Fold 3: 85%|████████▌ | 85/100 [00:42<00:07, 1.98 epochs/s, Training Loss=1.09e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 86%|████████▌ | 86/100 [00:42<00:07, 1.98 epochs/s, Training Loss=1.09e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 86%|████████▌ | 86/100 [00:43<00:07, 1.98 epochs/s, Training Loss=1.34e-5, Validation Loss=1.27e-5, Best Loss=1.01e-5]
Training Fold 3: 87%|████████▋ | 87/100 [00:43<00:06, 2.02 epochs/s, Training Loss=1.34e-5, Validation Loss=1.27e-5, Best Loss=1.01e-5]
Training Fold 3: 87%|████████▋ | 87/100 [00:43<00:06, 2.02 epochs/s, Training Loss=1.06e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 88%|████████▊ | 88/100 [00:43<00:06, 1.99 epochs/s, Training Loss=1.06e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 88%|████████▊ | 88/100 [00:44<00:06, 1.99 epochs/s, Training Loss=1.12e-5, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 3: 89%|████████▉ | 89/100 [00:44<00:05, 2.01 epochs/s, Training Loss=1.12e-5, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 3: 89%|████████▉ | 89/100 [00:44<00:05, 2.01 epochs/s, Training Loss=1.05e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 90%|█████████ | 90/100 [00:44<00:04, 2.01 epochs/s, Training Loss=1.05e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 90%|█████████ | 90/100 [00:45<00:04, 2.01 epochs/s, Training Loss=1.33e-5, Validation Loss=1.42e-5, Best Loss=1.01e-5]
Training Fold 3: 91%|█████████ | 91/100 [00:45<00:04, 2.03 epochs/s, Training Loss=1.33e-5, Validation Loss=1.42e-5, Best Loss=1.01e-5]
Training Fold 3: 91%|█████████ | 91/100 [00:45<00:04, 2.03 epochs/s, Training Loss=1.29e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 92%|█████████▏| 92/100 [00:45<00:04, 1.99 epochs/s, Training Loss=1.29e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 3: 92%|█████████▏| 92/100 [00:46<00:04, 1.99 epochs/s, Training Loss=1.81e-5, Validation Loss=1.67e-5, Best Loss=1.01e-5]
Training Fold 3: 93%|█████████▎| 93/100 [00:46<00:03, 1.97 epochs/s, Training Loss=1.81e-5, Validation Loss=1.67e-5, Best Loss=1.01e-5]
Training Fold 3: 93%|█████████▎| 93/100 [00:46<00:03, 1.97 epochs/s, Training Loss=1.28e-5, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 3: 94%|█████████▍| 94/100 [00:46<00:02, 2.00 epochs/s, Training Loss=1.28e-5, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 3: 94%|█████████▍| 94/100 [00:47<00:02, 2.00 epochs/s, Training Loss=1.17e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 95%|█████████▌| 95/100 [00:47<00:02, 2.02 epochs/s, Training Loss=1.17e-5, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 3: 95%|█████████▌| 95/100 [00:47<00:02, 2.02 epochs/s, Training Loss=1.3e-5, Validation Loss=1.35e-5, Best Loss=1.01e-5]
Training Fold 3: 96%|█████████▌| 96/100 [00:47<00:02, 1.92 epochs/s, Training Loss=1.3e-5, Validation Loss=1.35e-5, Best Loss=1.01e-5]
Training Fold 3: 96%|█████████▌| 96/100 [00:48<00:02, 1.92 epochs/s, Training Loss=1.3e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 97%|█████████▋| 97/100 [00:48<00:01, 1.94 epochs/s, Training Loss=1.3e-5, Validation Loss=1.29e-5, Best Loss=1.01e-5]
Training Fold 3: 97%|█████████▋| 97/100 [00:48<00:01, 1.94 epochs/s, Training Loss=1.09e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 98%|█████████▊| 98/100 [00:48<00:01, 1.94 epochs/s, Training Loss=1.09e-5, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 3: 98%|█████████▊| 98/100 [00:49<00:01, 1.94 epochs/s, Training Loss=1.33e-5, Validation Loss=1.45e-5, Best Loss=1.01e-5]
Training Fold 3: 99%|█████████▉| 99/100 [00:49<00:00, 1.99 epochs/s, Training Loss=1.33e-5, Validation Loss=1.45e-5, Best Loss=1.01e-5]
Training Fold 3: 99%|█████████▉| 99/100 [00:49<00:00, 1.99 epochs/s, Training Loss=1.09e-5, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 3: 100%|██████████| 100/100 [00:49<00:00, 2.01 epochs/s, Training Loss=1.09e-5, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 3: 100%|██████████| 100/100 [00:49<00:00, 2.01 epochs/s, Training Loss=1.09e-5, Validation Loss=1.14e-5, Best Loss=1.01e-5]
0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 4: 0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 4: 0%| | 0/100 [00:00<?, ? epochs/s, Training Loss=1.11e-5, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 4: 1%| | 1/100 [00:00<00:47, 2.08 epochs/s, Training Loss=1.11e-5, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 4: 1%| | 1/100 [00:01<00:47, 2.08 epochs/s, Training Loss=9.9e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 2%|▏ | 2/100 [00:01<00:49, 1.98 epochs/s, Training Loss=9.9e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 2%|▏ | 2/100 [00:01<00:49, 1.98 epochs/s, Training Loss=1.05e-5, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 3%|▎ | 3/100 [00:01<00:51, 1.90 epochs/s, Training Loss=1.05e-5, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 3%|▎ | 3/100 [00:02<00:51, 1.90 epochs/s, Training Loss=9.52e-6, Validation Loss=1.05e-5, Best Loss=1.01e-5]
Training Fold 4: 4%|▍ | 4/100 [00:02<00:49, 1.94 epochs/s, Training Loss=9.52e-6, Validation Loss=1.05e-5, Best Loss=1.01e-5]
Training Fold 4: 4%|▍ | 4/100 [00:02<00:49, 1.94 epochs/s, Training Loss=1.01e-5, Validation Loss=1.01e-5, Best Loss=1.01e-5]
Training Fold 4: 5%|▌ | 5/100 [00:02<00:49, 1.92 epochs/s, Training Loss=1.01e-5, Validation Loss=1.01e-5, Best Loss=1.01e-5]
Training Fold 4: 5%|▌ | 5/100 [00:03<00:49, 1.92 epochs/s, Training Loss=1.81e-5, Validation Loss=1.76e-5, Best Loss=1.01e-5]
Training Fold 4: 6%|▌ | 6/100 [00:03<00:48, 1.94 epochs/s, Training Loss=1.81e-5, Validation Loss=1.76e-5, Best Loss=1.01e-5]
Training Fold 4: 6%|▌ | 6/100 [00:03<00:48, 1.94 epochs/s, Training Loss=1.49e-5, Validation Loss=1.73e-5, Best Loss=1.01e-5]
Training Fold 4: 7%|▋ | 7/100 [00:03<00:46, 2.02 epochs/s, Training Loss=1.49e-5, Validation Loss=1.73e-5, Best Loss=1.01e-5]
Training Fold 4: 7%|▋ | 7/100 [00:04<00:46, 2.02 epochs/s, Training Loss=1.12e-5, Validation Loss=1.32e-5, Best Loss=1.01e-5]
Training Fold 4: 8%|▊ | 8/100 [00:04<00:45, 2.02 epochs/s, Training Loss=1.12e-5, Validation Loss=1.32e-5, Best Loss=1.01e-5]
Training Fold 4: 8%|▊ | 8/100 [00:04<00:45, 2.02 epochs/s, Training Loss=9.82e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 9%|▉ | 9/100 [00:04<00:44, 2.04 epochs/s, Training Loss=9.82e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 9%|▉ | 9/100 [00:05<00:44, 2.04 epochs/s, Training Loss=1.21e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 4: 10%|█ | 10/100 [00:05<00:45, 1.96 epochs/s, Training Loss=1.21e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 4: 10%|█ | 10/100 [00:05<00:45, 1.96 epochs/s, Training Loss=1.07e-5, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 4: 11%|█ | 11/100 [00:05<00:45, 1.94 epochs/s, Training Loss=1.07e-5, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 4: 11%|█ | 11/100 [00:06<00:45, 1.94 epochs/s, Training Loss=1.02e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 12%|█▏ | 12/100 [00:06<00:44, 1.96 epochs/s, Training Loss=1.02e-5, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 12%|█▏ | 12/100 [00:06<00:44, 1.96 epochs/s, Training Loss=1.18e-5, Validation Loss=1.31e-5, Best Loss=1.01e-5]
Training Fold 4: 13%|█▎ | 13/100 [00:06<00:43, 1.99 epochs/s, Training Loss=1.18e-5, Validation Loss=1.31e-5, Best Loss=1.01e-5]
Training Fold 4: 13%|█▎ | 13/100 [00:07<00:43, 1.99 epochs/s, Training Loss=1.04e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 4: 14%|█▍ | 14/100 [00:07<00:43, 1.98 epochs/s, Training Loss=1.04e-5, Validation Loss=1.19e-5, Best Loss=1.01e-5]
Training Fold 4: 14%|█▍ | 14/100 [00:07<00:43, 1.98 epochs/s, Training Loss=1.08e-5, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 4: 15%|█▌ | 15/100 [00:07<00:42, 2.00 epochs/s, Training Loss=1.08e-5, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 4: 15%|█▌ | 15/100 [00:08<00:42, 2.00 epochs/s, Training Loss=9.66e-6, Validation Loss=1.04e-5, Best Loss=1.01e-5]
Training Fold 4: 16%|█▌ | 16/100 [00:08<00:41, 2.03 epochs/s, Training Loss=9.66e-6, Validation Loss=1.04e-5, Best Loss=1.01e-5]
Training Fold 4: 16%|█▌ | 16/100 [00:08<00:41, 2.03 epochs/s, Training Loss=9.41e-6, Validation Loss=1.05e-5, Best Loss=1.01e-5]
Training Fold 4: 17%|█▋ | 17/100 [00:08<00:40, 2.03 epochs/s, Training Loss=9.41e-6, Validation Loss=1.05e-5, Best Loss=1.01e-5]
Training Fold 4: 17%|█▋ | 17/100 [00:09<00:40, 2.03 epochs/s, Training Loss=9.19e-6, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 18%|█▊ | 18/100 [00:09<00:40, 2.01 epochs/s, Training Loss=9.19e-6, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 18%|█▊ | 18/100 [00:09<00:40, 2.01 epochs/s, Training Loss=9.72e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 19%|█▉ | 19/100 [00:09<00:40, 2.01 epochs/s, Training Loss=9.72e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 19%|█▉ | 19/100 [00:10<00:40, 2.01 epochs/s, Training Loss=9.33e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 20%|██ | 20/100 [00:10<00:40, 1.98 epochs/s, Training Loss=9.33e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 20%|██ | 20/100 [00:10<00:40, 1.98 epochs/s, Training Loss=1e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 4: 21%|██ | 21/100 [00:10<00:39, 1.99 epochs/s, Training Loss=1e-5, Validation Loss=1.15e-5, Best Loss=1.01e-5]
Training Fold 4: 21%|██ | 21/100 [00:11<00:39, 1.99 epochs/s, Training Loss=9.48e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 22%|██▏ | 22/100 [00:11<00:39, 1.98 epochs/s, Training Loss=9.48e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 22%|██▏ | 22/100 [00:11<00:39, 1.98 epochs/s, Training Loss=9.86e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 23%|██▎ | 23/100 [00:11<00:39, 1.96 epochs/s, Training Loss=9.86e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 23%|██▎ | 23/100 [00:12<00:39, 1.96 epochs/s, Training Loss=1.06e-5, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 4: 24%|██▍ | 24/100 [00:12<00:38, 1.99 epochs/s, Training Loss=1.06e-5, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 4: 24%|██▍ | 24/100 [00:12<00:38, 1.99 epochs/s, Training Loss=1.1e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 4: 25%|██▌ | 25/100 [00:12<00:38, 1.97 epochs/s, Training Loss=1.1e-5, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 4: 25%|██▌ | 25/100 [00:13<00:38, 1.97 epochs/s, Training Loss=1.43e-5, Validation Loss=1.59e-5, Best Loss=1.01e-5]
Training Fold 4: 26%|██▌ | 26/100 [00:13<00:37, 2.00 epochs/s, Training Loss=1.43e-5, Validation Loss=1.59e-5, Best Loss=1.01e-5]
Training Fold 4: 26%|██▌ | 26/100 [00:13<00:37, 2.00 epochs/s, Training Loss=8.76e-6, Validation Loss=1.02e-5, Best Loss=1.01e-5]
Training Fold 4: 27%|██▋ | 27/100 [00:13<00:36, 2.02 epochs/s, Training Loss=8.76e-6, Validation Loss=1.02e-5, Best Loss=1.01e-5]
Training Fold 4: 27%|██▋ | 27/100 [00:14<00:36, 2.02 epochs/s, Training Loss=9.19e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 28%|██▊ | 28/100 [00:14<00:35, 2.03 epochs/s, Training Loss=9.19e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 28%|██▊ | 28/100 [00:14<00:35, 2.03 epochs/s, Training Loss=9.76e-6, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 4: 29%|██▉ | 29/100 [00:14<00:35, 2.03 epochs/s, Training Loss=9.76e-6, Validation Loss=1.16e-5, Best Loss=1.01e-5]
Training Fold 4: 29%|██▉ | 29/100 [00:15<00:35, 2.03 epochs/s, Training Loss=8.61e-6, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 30%|███ | 30/100 [00:15<00:34, 2.01 epochs/s, Training Loss=8.61e-6, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 30%|███ | 30/100 [00:15<00:34, 2.01 epochs/s, Training Loss=1.04e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 4: 31%|███ | 31/100 [00:15<00:34, 2.03 epochs/s, Training Loss=1.04e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 4: 31%|███ | 31/100 [00:16<00:34, 2.03 epochs/s, Training Loss=8.69e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 32%|███▏ | 32/100 [00:16<00:34, 1.99 epochs/s, Training Loss=8.69e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 32%|███▏ | 32/100 [00:16<00:34, 1.99 epochs/s, Training Loss=8.83e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 33%|███▎ | 33/100 [00:16<00:33, 1.98 epochs/s, Training Loss=8.83e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 33%|███▎ | 33/100 [00:17<00:33, 1.98 epochs/s, Training Loss=8.98e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 34%|███▍ | 34/100 [00:17<00:33, 1.97 epochs/s, Training Loss=8.98e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 34%|███▍ | 34/100 [00:17<00:33, 1.97 epochs/s, Training Loss=9.18e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 35%|███▌ | 35/100 [00:17<00:32, 2.02 epochs/s, Training Loss=9.18e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 35%|███▌ | 35/100 [00:18<00:32, 2.02 epochs/s, Training Loss=8.43e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 36%|███▌ | 36/100 [00:18<00:32, 1.99 epochs/s, Training Loss=8.43e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 36%|███▌ | 36/100 [00:18<00:32, 1.99 epochs/s, Training Loss=8.78e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 37%|███▋ | 37/100 [00:18<00:31, 1.99 epochs/s, Training Loss=8.78e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 37%|███▋ | 37/100 [00:19<00:31, 1.99 epochs/s, Training Loss=9.5e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 38%|███▊ | 38/100 [00:19<00:31, 1.99 epochs/s, Training Loss=9.5e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 38%|███▊ | 38/100 [00:19<00:31, 1.99 epochs/s, Training Loss=1.07e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 39%|███▉ | 39/100 [00:19<00:30, 1.98 epochs/s, Training Loss=1.07e-5, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 39%|███▉ | 39/100 [00:20<00:30, 1.98 epochs/s, Training Loss=1.05e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 4: 40%|████ | 40/100 [00:20<00:30, 1.96 epochs/s, Training Loss=1.05e-5, Validation Loss=1.28e-5, Best Loss=1.01e-5]
Training Fold 4: 40%|████ | 40/100 [00:20<00:30, 1.96 epochs/s, Training Loss=8.93e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 41%|████ | 41/100 [00:20<00:29, 1.98 epochs/s, Training Loss=8.93e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 41%|████ | 41/100 [00:21<00:29, 1.98 epochs/s, Training Loss=8.97e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 42%|████▏ | 42/100 [00:21<00:29, 1.98 epochs/s, Training Loss=8.97e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 42%|████▏ | 42/100 [00:21<00:29, 1.98 epochs/s, Training Loss=8.97e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 43%|████▎ | 43/100 [00:21<00:27, 2.04 epochs/s, Training Loss=8.97e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 43%|████▎ | 43/100 [00:22<00:27, 2.04 epochs/s, Training Loss=1.23e-5, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 4: 44%|████▍ | 44/100 [00:22<00:27, 2.06 epochs/s, Training Loss=1.23e-5, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 4: 44%|████▍ | 44/100 [00:22<00:27, 2.06 epochs/s, Training Loss=9.61e-6, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 4: 45%|████▌ | 45/100 [00:22<00:27, 2.04 epochs/s, Training Loss=9.61e-6, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 4: 45%|████▌ | 45/100 [00:23<00:27, 2.04 epochs/s, Training Loss=9.53e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 46%|████▌ | 46/100 [00:23<00:26, 2.02 epochs/s, Training Loss=9.53e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 46%|████▌ | 46/100 [00:23<00:26, 2.02 epochs/s, Training Loss=8.57e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 47%|████▋ | 47/100 [00:23<00:26, 2.02 epochs/s, Training Loss=8.57e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 47%|████▋ | 47/100 [00:24<00:26, 2.02 epochs/s, Training Loss=2.47e-5, Validation Loss=2.67e-5, Best Loss=1.01e-5]
Training Fold 4: 48%|████▊ | 48/100 [00:24<00:26, 1.99 epochs/s, Training Loss=2.47e-5, Validation Loss=2.67e-5, Best Loss=1.01e-5]
Training Fold 4: 48%|████▊ | 48/100 [00:24<00:26, 1.99 epochs/s, Training Loss=8.85e-6, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 4: 49%|████▉ | 49/100 [00:24<00:25, 2.00 epochs/s, Training Loss=8.85e-6, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 4: 49%|████▉ | 49/100 [00:25<00:25, 2.00 epochs/s, Training Loss=8.38e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 50%|█████ | 50/100 [00:25<00:24, 2.05 epochs/s, Training Loss=8.38e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 50%|█████ | 50/100 [00:25<00:24, 2.05 epochs/s, Training Loss=9.32e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 51%|█████ | 51/100 [00:25<00:24, 2.03 epochs/s, Training Loss=9.32e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 51%|█████ | 51/100 [00:26<00:24, 2.03 epochs/s, Training Loss=1.15e-5, Validation Loss=1.42e-5, Best Loss=1.01e-5]
Training Fold 4: 52%|█████▏ | 52/100 [00:26<00:23, 2.02 epochs/s, Training Loss=1.15e-5, Validation Loss=1.42e-5, Best Loss=1.01e-5]
Training Fold 4: 52%|█████▏ | 52/100 [00:26<00:23, 2.02 epochs/s, Training Loss=7.98e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 53%|█████▎ | 53/100 [00:26<00:23, 2.04 epochs/s, Training Loss=7.98e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 53%|█████▎ | 53/100 [00:27<00:23, 2.04 epochs/s, Training Loss=8.77e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 54%|█████▍ | 54/100 [00:27<00:22, 2.01 epochs/s, Training Loss=8.77e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 54%|█████▍ | 54/100 [00:27<00:22, 2.01 epochs/s, Training Loss=8.37e-6, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 4: 55%|█████▌ | 55/100 [00:27<00:22, 2.04 epochs/s, Training Loss=8.37e-6, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 4: 55%|█████▌ | 55/100 [00:27<00:22, 2.04 epochs/s, Training Loss=9e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 56%|█████▌ | 56/100 [00:27<00:21, 2.05 epochs/s, Training Loss=9e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 56%|█████▌ | 56/100 [00:28<00:21, 2.05 epochs/s, Training Loss=9.35e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 57%|█████▋ | 57/100 [00:28<00:20, 2.05 epochs/s, Training Loss=9.35e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 57%|█████▋ | 57/100 [00:28<00:20, 2.05 epochs/s, Training Loss=7.06e-5, Validation Loss=7.42e-5, Best Loss=1.01e-5]
Training Fold 4: 58%|█████▊ | 58/100 [00:28<00:20, 2.07 epochs/s, Training Loss=7.06e-5, Validation Loss=7.42e-5, Best Loss=1.01e-5]
Training Fold 4: 58%|█████▊ | 58/100 [00:29<00:20, 2.07 epochs/s, Training Loss=9.3e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 59%|█████▉ | 59/100 [00:29<00:20, 2.03 epochs/s, Training Loss=9.3e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 59%|█████▉ | 59/100 [00:29<00:20, 2.03 epochs/s, Training Loss=9.77e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 60%|██████ | 60/100 [00:29<00:19, 2.06 epochs/s, Training Loss=9.77e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 60%|██████ | 60/100 [00:30<00:19, 2.06 epochs/s, Training Loss=8.57e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 61%|██████ | 61/100 [00:30<00:18, 2.06 epochs/s, Training Loss=8.57e-6, Validation Loss=1.06e-5, Best Loss=1.01e-5]
Training Fold 4: 61%|██████ | 61/100 [00:30<00:18, 2.06 epochs/s, Training Loss=8.63e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 62%|██████▏ | 62/100 [00:30<00:18, 2.05 epochs/s, Training Loss=8.63e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 62%|██████▏ | 62/100 [00:31<00:18, 2.05 epochs/s, Training Loss=1.29e-5, Validation Loss=1.62e-5, Best Loss=1.01e-5]
Training Fold 4: 63%|██████▎ | 63/100 [00:31<00:18, 2.03 epochs/s, Training Loss=1.29e-5, Validation Loss=1.62e-5, Best Loss=1.01e-5]
Training Fold 4: 63%|██████▎ | 63/100 [00:31<00:18, 2.03 epochs/s, Training Loss=8.1e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 64%|██████▍ | 64/100 [00:31<00:17, 2.01 epochs/s, Training Loss=8.1e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 64%|██████▍ | 64/100 [00:32<00:17, 2.01 epochs/s, Training Loss=8.98e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 65%|██████▌ | 65/100 [00:32<00:17, 2.01 epochs/s, Training Loss=8.98e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 65%|██████▌ | 65/100 [00:32<00:17, 2.01 epochs/s, Training Loss=1.02e-5, Validation Loss=1.24e-5, Best Loss=1.01e-5]
Training Fold 4: 66%|██████▌ | 66/100 [00:32<00:16, 2.03 epochs/s, Training Loss=1.02e-5, Validation Loss=1.24e-5, Best Loss=1.01e-5]
Training Fold 4: 66%|██████▌ | 66/100 [00:33<00:16, 2.03 epochs/s, Training Loss=9.53e-6, Validation Loss=1.26e-5, Best Loss=1.01e-5]
Training Fold 4: 67%|██████▋ | 67/100 [00:33<00:16, 1.97 epochs/s, Training Loss=9.53e-6, Validation Loss=1.26e-5, Best Loss=1.01e-5]
Training Fold 4: 67%|██████▋ | 67/100 [00:33<00:16, 1.97 epochs/s, Training Loss=8.62e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 68%|██████▊ | 68/100 [00:33<00:16, 1.93 epochs/s, Training Loss=8.62e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 68%|██████▊ | 68/100 [00:34<00:16, 1.93 epochs/s, Training Loss=4.96e-5, Validation Loss=5.26e-5, Best Loss=1.01e-5]
Training Fold 4: 69%|██████▉ | 69/100 [00:34<00:15, 1.94 epochs/s, Training Loss=4.96e-5, Validation Loss=5.26e-5, Best Loss=1.01e-5]
Training Fold 4: 69%|██████▉ | 69/100 [00:35<00:15, 1.94 epochs/s, Training Loss=1.03e-5, Validation Loss=1.35e-5, Best Loss=1.01e-5]
Training Fold 4: 70%|███████ | 70/100 [00:35<00:15, 1.93 epochs/s, Training Loss=1.03e-5, Validation Loss=1.35e-5, Best Loss=1.01e-5]
Training Fold 4: 70%|███████ | 70/100 [00:35<00:15, 1.93 epochs/s, Training Loss=9.24e-6, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 4: 71%|███████ | 71/100 [00:35<00:14, 1.96 epochs/s, Training Loss=9.24e-6, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 4: 71%|███████ | 71/100 [00:36<00:14, 1.96 epochs/s, Training Loss=9.03e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 72%|███████▏ | 72/100 [00:36<00:14, 1.96 epochs/s, Training Loss=9.03e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 72%|███████▏ | 72/100 [00:36<00:14, 1.96 epochs/s, Training Loss=9.02e-6, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 4: 73%|███████▎ | 73/100 [00:36<00:13, 1.98 epochs/s, Training Loss=9.02e-6, Validation Loss=1.21e-5, Best Loss=1.01e-5]
Training Fold 4: 73%|███████▎ | 73/100 [00:37<00:13, 1.98 epochs/s, Training Loss=1.13e-5, Validation Loss=1.53e-5, Best Loss=1.01e-5]
Training Fold 4: 74%|███████▍ | 74/100 [00:37<00:13, 1.95 epochs/s, Training Loss=1.13e-5, Validation Loss=1.53e-5, Best Loss=1.01e-5]
Training Fold 4: 74%|███████▍ | 74/100 [00:37<00:13, 1.95 epochs/s, Training Loss=7.76e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 75%|███████▌ | 75/100 [00:37<00:12, 1.95 epochs/s, Training Loss=7.76e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 75%|███████▌ | 75/100 [00:38<00:12, 1.95 epochs/s, Training Loss=7.39e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 76%|███████▌ | 76/100 [00:38<00:12, 1.96 epochs/s, Training Loss=7.39e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 76%|███████▌ | 76/100 [00:38<00:12, 1.96 epochs/s, Training Loss=8.38e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 77%|███████▋ | 77/100 [00:38<00:11, 1.97 epochs/s, Training Loss=8.38e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 77%|███████▋ | 77/100 [00:39<00:11, 1.97 epochs/s, Training Loss=7.43e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 78%|███████▊ | 78/100 [00:39<00:10, 2.00 epochs/s, Training Loss=7.43e-6, Validation Loss=1.1e-5, Best Loss=1.01e-5]
Training Fold 4: 78%|███████▊ | 78/100 [00:39<00:10, 2.00 epochs/s, Training Loss=8.33e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 79%|███████▉ | 79/100 [00:39<00:10, 1.98 epochs/s, Training Loss=8.33e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 79%|███████▉ | 79/100 [00:40<00:10, 1.98 epochs/s, Training Loss=1.36e-5, Validation Loss=1.84e-5, Best Loss=1.01e-5]
Training Fold 4: 80%|████████ | 80/100 [00:40<00:10, 1.96 epochs/s, Training Loss=1.36e-5, Validation Loss=1.84e-5, Best Loss=1.01e-5]
Training Fold 4: 80%|████████ | 80/100 [00:40<00:10, 1.96 epochs/s, Training Loss=7.61e-6, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 4: 81%|████████ | 81/100 [00:40<00:09, 2.00 epochs/s, Training Loss=7.61e-6, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 4: 81%|████████ | 81/100 [00:41<00:09, 2.00 epochs/s, Training Loss=8.13e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 82%|████████▏ | 82/100 [00:41<00:09, 1.99 epochs/s, Training Loss=8.13e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 82%|████████▏ | 82/100 [00:41<00:09, 1.99 epochs/s, Training Loss=8.77e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 83%|████████▎ | 83/100 [00:41<00:08, 2.03 epochs/s, Training Loss=8.77e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 83%|████████▎ | 83/100 [00:42<00:08, 2.03 epochs/s, Training Loss=7.25e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 84%|████████▍ | 84/100 [00:42<00:07, 2.02 epochs/s, Training Loss=7.25e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 84%|████████▍ | 84/100 [00:42<00:07, 2.02 epochs/s, Training Loss=8.31e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 85%|████████▌ | 85/100 [00:42<00:07, 2.01 epochs/s, Training Loss=8.31e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 85%|████████▌ | 85/100 [00:43<00:07, 2.01 epochs/s, Training Loss=7.49e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 86%|████████▌ | 86/100 [00:43<00:06, 2.00 epochs/s, Training Loss=7.49e-6, Validation Loss=1.12e-5, Best Loss=1.01e-5]
Training Fold 4: 86%|████████▌ | 86/100 [00:43<00:06, 2.00 epochs/s, Training Loss=9.18e-6, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 4: 87%|████████▋ | 87/100 [00:43<00:06, 2.04 epochs/s, Training Loss=9.18e-6, Validation Loss=1.3e-5, Best Loss=1.01e-5]
Training Fold 4: 87%|████████▋ | 87/100 [00:44<00:06, 2.04 epochs/s, Training Loss=7.37e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 88%|████████▊ | 88/100 [00:44<00:05, 2.01 epochs/s, Training Loss=7.37e-6, Validation Loss=1.07e-5, Best Loss=1.01e-5]
Training Fold 4: 88%|████████▊ | 88/100 [00:44<00:05, 2.01 epochs/s, Training Loss=9.25e-6, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 4: 89%|████████▉ | 89/100 [00:44<00:05, 1.99 epochs/s, Training Loss=9.25e-6, Validation Loss=1.34e-5, Best Loss=1.01e-5]
Training Fold 4: 89%|████████▉ | 89/100 [00:45<00:05, 1.99 epochs/s, Training Loss=8.26e-6, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 4: 90%|█████████ | 90/100 [00:45<00:05, 1.98 epochs/s, Training Loss=8.26e-6, Validation Loss=1.22e-5, Best Loss=1.01e-5]
Training Fold 4: 90%|█████████ | 90/100 [00:45<00:05, 1.98 epochs/s, Training Loss=8.26e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 91%|█████████ | 91/100 [00:45<00:04, 1.96 epochs/s, Training Loss=8.26e-6, Validation Loss=1.13e-5, Best Loss=1.01e-5]
Training Fold 4: 91%|█████████ | 91/100 [00:46<00:04, 1.96 epochs/s, Training Loss=8.41e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 92%|█████████▏| 92/100 [00:46<00:04, 1.95 epochs/s, Training Loss=8.41e-6, Validation Loss=1.18e-5, Best Loss=1.01e-5]
Training Fold 4: 92%|█████████▏| 92/100 [00:46<00:04, 1.95 epochs/s, Training Loss=7.54e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 93%|█████████▎| 93/100 [00:46<00:03, 1.99 epochs/s, Training Loss=7.54e-6, Validation Loss=1.09e-5, Best Loss=1.01e-5]
Training Fold 4: 93%|█████████▎| 93/100 [00:47<00:03, 1.99 epochs/s, Training Loss=1.24e-5, Validation Loss=1.4e-5, Best Loss=1.01e-5]
Training Fold 4: 94%|█████████▍| 94/100 [00:47<00:03, 1.98 epochs/s, Training Loss=1.24e-5, Validation Loss=1.4e-5, Best Loss=1.01e-5]
Training Fold 4: 94%|█████████▍| 94/100 [00:47<00:03, 1.98 epochs/s, Training Loss=8.72e-6, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 4: 95%|█████████▌| 95/100 [00:47<00:02, 2.02 epochs/s, Training Loss=8.72e-6, Validation Loss=1.11e-5, Best Loss=1.01e-5]
Training Fold 4: 95%|█████████▌| 95/100 [00:48<00:02, 2.02 epochs/s, Training Loss=8.8e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 96%|█████████▌| 96/100 [00:48<00:02, 1.99 epochs/s, Training Loss=8.8e-6, Validation Loss=1.2e-5, Best Loss=1.01e-5]
Training Fold 4: 96%|█████████▌| 96/100 [00:48<00:02, 1.99 epochs/s, Training Loss=7.55e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 97%|█████████▋| 97/100 [00:48<00:01, 2.01 epochs/s, Training Loss=7.55e-6, Validation Loss=1.17e-5, Best Loss=1.01e-5]
Training Fold 4: 97%|█████████▋| 97/100 [00:49<00:01, 2.01 epochs/s, Training Loss=7.52e-6, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 98%|█████████▊| 98/100 [00:49<00:01, 1.96 epochs/s, Training Loss=7.52e-6, Validation Loss=1.08e-5, Best Loss=1.01e-5]
Training Fold 4: 98%|█████████▊| 98/100 [00:49<00:01, 1.96 epochs/s, Training Loss=8.89e-6, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 4: 99%|█████████▉| 99/100 [00:49<00:00, 1.98 epochs/s, Training Loss=8.89e-6, Validation Loss=1.25e-5, Best Loss=1.01e-5]
Training Fold 4: 99%|█████████▉| 99/100 [00:50<00:00, 1.98 epochs/s, Training Loss=7.65e-6, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 4: 100%|██████████| 100/100 [00:50<00:00, 2.02 epochs/s, Training Loss=7.65e-6, Validation Loss=1.14e-5, Best Loss=1.01e-5]
Training Fold 4: 100%|██████████| 100/100 [00:50<00:00, 2.00 epochs/s, Training Loss=7.65e-6, Validation Loss=1.14e-5, Best Loss=1.01e-5]
0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 5: 0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 5: 0%| | 0/100 [00:00<?, ? epochs/s, Training Loss=1.05e-5, Validation Loss=7.88e-6, Best Loss=7.88e-6]
Training Fold 5: 1%| | 1/100 [00:00<00:47, 2.10 epochs/s, Training Loss=1.05e-5, Validation Loss=7.88e-6, Best Loss=7.88e-6]
Training Fold 5: 1%| | 1/100 [00:01<00:47, 2.10 epochs/s, Training Loss=8.65e-6, Validation Loss=7.24e-6, Best Loss=7.24e-6]
Training Fold 5: 2%|▏ | 2/100 [00:01<00:49, 1.98 epochs/s, Training Loss=8.65e-6, Validation Loss=7.24e-6, Best Loss=7.24e-6]
Training Fold 5: 2%|▏ | 2/100 [00:01<00:49, 1.98 epochs/s, Training Loss=1.07e-5, Validation Loss=1.05e-5, Best Loss=7.24e-6]
Training Fold 5: 3%|▎ | 3/100 [00:01<00:48, 2.00 epochs/s, Training Loss=1.07e-5, Validation Loss=1.05e-5, Best Loss=7.24e-6]
Training Fold 5: 3%|▎ | 3/100 [00:02<00:48, 2.00 epochs/s, Training Loss=8.93e-6, Validation Loss=7.4e-6, Best Loss=7.24e-6]
Training Fold 5: 4%|▍ | 4/100 [00:02<00:48, 1.99 epochs/s, Training Loss=8.93e-6, Validation Loss=7.4e-6, Best Loss=7.24e-6]
Training Fold 5: 4%|▍ | 4/100 [00:02<00:48, 1.99 epochs/s, Training Loss=8.74e-6, Validation Loss=8e-6, Best Loss=7.24e-6]
Training Fold 5: 5%|▌ | 5/100 [00:02<00:46, 2.03 epochs/s, Training Loss=8.74e-6, Validation Loss=8e-6, Best Loss=7.24e-6]
Training Fold 5: 5%|▌ | 5/100 [00:02<00:46, 2.03 epochs/s, Training Loss=9.42e-6, Validation Loss=8.63e-6, Best Loss=7.24e-6]
Training Fold 5: 6%|▌ | 6/100 [00:02<00:45, 2.05 epochs/s, Training Loss=9.42e-6, Validation Loss=8.63e-6, Best Loss=7.24e-6]
Training Fold 5: 6%|▌ | 6/100 [00:03<00:45, 2.05 epochs/s, Training Loss=1.01e-5, Validation Loss=9.37e-6, Best Loss=7.24e-6]
Training Fold 5: 7%|▋ | 7/100 [00:03<00:46, 1.99 epochs/s, Training Loss=1.01e-5, Validation Loss=9.37e-6, Best Loss=7.24e-6]
Training Fold 5: 7%|▋ | 7/100 [00:03<00:46, 1.99 epochs/s, Training Loss=8.54e-6, Validation Loss=7.43e-6, Best Loss=7.24e-6]
Training Fold 5: 8%|▊ | 8/100 [00:03<00:46, 1.98 epochs/s, Training Loss=8.54e-6, Validation Loss=7.43e-6, Best Loss=7.24e-6]
Training Fold 5: 8%|▊ | 8/100 [00:04<00:46, 1.98 epochs/s, Training Loss=1.08e-5, Validation Loss=1.12e-5, Best Loss=7.24e-6]
Training Fold 5: 9%|▉ | 9/100 [00:04<00:46, 1.98 epochs/s, Training Loss=1.08e-5, Validation Loss=1.12e-5, Best Loss=7.24e-6]
Training Fold 5: 9%|▉ | 9/100 [00:05<00:46, 1.98 epochs/s, Training Loss=9.2e-6, Validation Loss=9.11e-6, Best Loss=7.24e-6]
Training Fold 5: 10%|█ | 10/100 [00:05<00:46, 1.95 epochs/s, Training Loss=9.2e-6, Validation Loss=9.11e-6, Best Loss=7.24e-6]
Training Fold 5: 10%|█ | 10/100 [00:05<00:46, 1.95 epochs/s, Training Loss=8.23e-6, Validation Loss=8.3e-6, Best Loss=7.24e-6]
Training Fold 5: 11%|█ | 11/100 [00:05<00:45, 1.96 epochs/s, Training Loss=8.23e-6, Validation Loss=8.3e-6, Best Loss=7.24e-6]
Training Fold 5: 11%|█ | 11/100 [00:06<00:45, 1.96 epochs/s, Training Loss=1e-5, Validation Loss=9.5e-6, Best Loss=7.24e-6]
Training Fold 5: 12%|█▏ | 12/100 [00:06<00:45, 1.95 epochs/s, Training Loss=1e-5, Validation Loss=9.5e-6, Best Loss=7.24e-6]
Training Fold 5: 12%|█▏ | 12/100 [00:06<00:45, 1.95 epochs/s, Training Loss=9.88e-6, Validation Loss=8.61e-6, Best Loss=7.24e-6]
Training Fold 5: 13%|█▎ | 13/100 [00:06<00:44, 1.96 epochs/s, Training Loss=9.88e-6, Validation Loss=8.61e-6, Best Loss=7.24e-6]
Training Fold 5: 13%|█▎ | 13/100 [00:07<00:44, 1.96 epochs/s, Training Loss=1.51e-5, Validation Loss=1.54e-5, Best Loss=7.24e-6]
Training Fold 5: 14%|█▍ | 14/100 [00:07<00:43, 1.96 epochs/s, Training Loss=1.51e-5, Validation Loss=1.54e-5, Best Loss=7.24e-6]
Training Fold 5: 14%|█▍ | 14/100 [00:07<00:43, 1.96 epochs/s, Training Loss=8.55e-6, Validation Loss=8.44e-6, Best Loss=7.24e-6]
Training Fold 5: 15%|█▌ | 15/100 [00:07<00:43, 1.94 epochs/s, Training Loss=8.55e-6, Validation Loss=8.44e-6, Best Loss=7.24e-6]
Training Fold 5: 15%|█▌ | 15/100 [00:08<00:43, 1.94 epochs/s, Training Loss=8.13e-6, Validation Loss=8.08e-6, Best Loss=7.24e-6]
Training Fold 5: 16%|█▌ | 16/100 [00:08<00:42, 1.96 epochs/s, Training Loss=8.13e-6, Validation Loss=8.08e-6, Best Loss=7.24e-6]
Training Fold 5: 16%|█▌ | 16/100 [00:08<00:42, 1.96 epochs/s, Training Loss=7.29e-6, Validation Loss=7.58e-6, Best Loss=7.24e-6]
Training Fold 5: 17%|█▋ | 17/100 [00:08<00:42, 1.93 epochs/s, Training Loss=7.29e-6, Validation Loss=7.58e-6, Best Loss=7.24e-6]
Training Fold 5: 17%|█▋ | 17/100 [00:09<00:42, 1.93 epochs/s, Training Loss=8.21e-6, Validation Loss=8.65e-6, Best Loss=7.24e-6]
Training Fold 5: 18%|█▊ | 18/100 [00:09<00:42, 1.94 epochs/s, Training Loss=8.21e-6, Validation Loss=8.65e-6, Best Loss=7.24e-6]
Training Fold 5: 18%|█▊ | 18/100 [00:09<00:42, 1.94 epochs/s, Training Loss=8.51e-6, Validation Loss=8.71e-6, Best Loss=7.24e-6]
Training Fold 5: 19%|█▉ | 19/100 [00:09<00:41, 1.93 epochs/s, Training Loss=8.51e-6, Validation Loss=8.71e-6, Best Loss=7.24e-6]
Training Fold 5: 19%|█▉ | 19/100 [00:10<00:41, 1.93 epochs/s, Training Loss=8.58e-6, Validation Loss=7.76e-6, Best Loss=7.24e-6]
Training Fold 5: 20%|██ | 20/100 [00:10<00:40, 1.95 epochs/s, Training Loss=8.58e-6, Validation Loss=7.76e-6, Best Loss=7.24e-6]
Training Fold 5: 20%|██ | 20/100 [00:10<00:40, 1.95 epochs/s, Training Loss=7.71e-6, Validation Loss=8.87e-6, Best Loss=7.24e-6]
Training Fold 5: 21%|██ | 21/100 [00:10<00:40, 1.93 epochs/s, Training Loss=7.71e-6, Validation Loss=8.87e-6, Best Loss=7.24e-6]
Training Fold 5: 21%|██ | 21/100 [00:11<00:40, 1.93 epochs/s, Training Loss=8.13e-6, Validation Loss=8.06e-6, Best Loss=7.24e-6]
Training Fold 5: 22%|██▏ | 22/100 [00:11<00:40, 1.95 epochs/s, Training Loss=8.13e-6, Validation Loss=8.06e-6, Best Loss=7.24e-6]
Training Fold 5: 22%|██▏ | 22/100 [00:11<00:40, 1.95 epochs/s, Training Loss=2.82e-5, Validation Loss=2.6e-5, Best Loss=7.24e-6]
Training Fold 5: 23%|██▎ | 23/100 [00:11<00:39, 1.94 epochs/s, Training Loss=2.82e-5, Validation Loss=2.6e-5, Best Loss=7.24e-6]
Training Fold 5: 23%|██▎ | 23/100 [00:12<00:39, 1.94 epochs/s, Training Loss=1.16e-5, Validation Loss=1.08e-5, Best Loss=7.24e-6]
Training Fold 5: 24%|██▍ | 24/100 [00:12<00:39, 1.94 epochs/s, Training Loss=1.16e-5, Validation Loss=1.08e-5, Best Loss=7.24e-6]
Training Fold 5: 24%|██▍ | 24/100 [00:12<00:39, 1.94 epochs/s, Training Loss=9.62e-6, Validation Loss=1.01e-5, Best Loss=7.24e-6]
Training Fold 5: 25%|██▌ | 25/100 [00:12<00:38, 1.96 epochs/s, Training Loss=9.62e-6, Validation Loss=1.01e-5, Best Loss=7.24e-6]
Training Fold 5: 25%|██▌ | 25/100 [00:13<00:38, 1.96 epochs/s, Training Loss=8.79e-6, Validation Loss=8.38e-6, Best Loss=7.24e-6]
Training Fold 5: 26%|██▌ | 26/100 [00:13<00:37, 1.97 epochs/s, Training Loss=8.79e-6, Validation Loss=8.38e-6, Best Loss=7.24e-6]
Training Fold 5: 26%|██▌ | 26/100 [00:13<00:37, 1.97 epochs/s, Training Loss=9.37e-6, Validation Loss=9.16e-6, Best Loss=7.24e-6]
Training Fold 5: 27%|██▋ | 27/100 [00:13<00:37, 1.96 epochs/s, Training Loss=9.37e-6, Validation Loss=9.16e-6, Best Loss=7.24e-6]
Training Fold 5: 27%|██▋ | 27/100 [00:14<00:37, 1.96 epochs/s, Training Loss=9.65e-6, Validation Loss=9.28e-6, Best Loss=7.24e-6]
Training Fold 5: 28%|██▊ | 28/100 [00:14<00:36, 1.97 epochs/s, Training Loss=9.65e-6, Validation Loss=9.28e-6, Best Loss=7.24e-6]
Training Fold 5: 28%|██▊ | 28/100 [00:14<00:36, 1.97 epochs/s, Training Loss=8.2e-6, Validation Loss=8.76e-6, Best Loss=7.24e-6]
Training Fold 5: 29%|██▉ | 29/100 [00:14<00:36, 1.96 epochs/s, Training Loss=8.2e-6, Validation Loss=8.76e-6, Best Loss=7.24e-6]
Training Fold 5: 29%|██▉ | 29/100 [00:15<00:36, 1.96 epochs/s, Training Loss=8.88e-6, Validation Loss=9.18e-6, Best Loss=7.24e-6]
Training Fold 5: 30%|███ | 30/100 [00:15<00:35, 1.96 epochs/s, Training Loss=8.88e-6, Validation Loss=9.18e-6, Best Loss=7.24e-6]
Training Fold 5: 30%|███ | 30/100 [00:15<00:35, 1.96 epochs/s, Training Loss=8.07e-6, Validation Loss=8.03e-6, Best Loss=7.24e-6]
Training Fold 5: 31%|███ | 31/100 [00:15<00:35, 1.93 epochs/s, Training Loss=8.07e-6, Validation Loss=8.03e-6, Best Loss=7.24e-6]
Training Fold 5: 31%|███ | 31/100 [00:16<00:35, 1.93 epochs/s, Training Loss=9.08e-6, Validation Loss=8.29e-6, Best Loss=7.24e-6]
Training Fold 5: 32%|███▏ | 32/100 [00:16<00:35, 1.90 epochs/s, Training Loss=9.08e-6, Validation Loss=8.29e-6, Best Loss=7.24e-6]
Training Fold 5: 32%|███▏ | 32/100 [00:16<00:35, 1.90 epochs/s, Training Loss=2.58e-5, Validation Loss=2.63e-5, Best Loss=7.24e-6]
Training Fold 5: 33%|███▎ | 33/100 [00:16<00:35, 1.90 epochs/s, Training Loss=2.58e-5, Validation Loss=2.63e-5, Best Loss=7.24e-6]
Training Fold 5: 33%|███▎ | 33/100 [00:17<00:35, 1.90 epochs/s, Training Loss=9.11e-6, Validation Loss=9.45e-6, Best Loss=7.24e-6]
Training Fold 5: 34%|███▍ | 34/100 [00:17<00:33, 1.94 epochs/s, Training Loss=9.11e-6, Validation Loss=9.45e-6, Best Loss=7.24e-6]
Training Fold 5: 34%|███▍ | 34/100 [00:17<00:33, 1.94 epochs/s, Training Loss=8.52e-6, Validation Loss=1.06e-5, Best Loss=7.24e-6]
Training Fold 5: 35%|███▌ | 35/100 [00:17<00:33, 1.94 epochs/s, Training Loss=8.52e-6, Validation Loss=1.06e-5, Best Loss=7.24e-6]
Training Fold 5: 35%|███▌ | 35/100 [00:18<00:33, 1.94 epochs/s, Training Loss=1.29e-5, Validation Loss=1.49e-5, Best Loss=7.24e-6]
Training Fold 5: 36%|███▌ | 36/100 [00:18<00:32, 1.97 epochs/s, Training Loss=1.29e-5, Validation Loss=1.49e-5, Best Loss=7.24e-6]
Training Fold 5: 36%|███▌ | 36/100 [00:18<00:32, 1.97 epochs/s, Training Loss=1.05e-5, Validation Loss=1.22e-5, Best Loss=7.24e-6]
Training Fold 5: 37%|███▋ | 37/100 [00:18<00:31, 1.97 epochs/s, Training Loss=1.05e-5, Validation Loss=1.22e-5, Best Loss=7.24e-6]
Training Fold 5: 37%|███▋ | 37/100 [00:19<00:31, 1.97 epochs/s, Training Loss=8.49e-6, Validation Loss=1.09e-5, Best Loss=7.24e-6]
Training Fold 5: 38%|███▊ | 38/100 [00:19<00:31, 1.97 epochs/s, Training Loss=8.49e-6, Validation Loss=1.09e-5, Best Loss=7.24e-6]
Training Fold 5: 38%|███▊ | 38/100 [00:19<00:31, 1.97 epochs/s, Training Loss=7.56e-6, Validation Loss=7.97e-6, Best Loss=7.24e-6]
Training Fold 5: 39%|███▉ | 39/100 [00:19<00:32, 1.89 epochs/s, Training Loss=7.56e-6, Validation Loss=7.97e-6, Best Loss=7.24e-6]
Training Fold 5: 39%|███▉ | 39/100 [00:20<00:32, 1.89 epochs/s, Training Loss=9.49e-6, Validation Loss=8.68e-6, Best Loss=7.24e-6]
Training Fold 5: 40%|████ | 40/100 [00:20<00:31, 1.88 epochs/s, Training Loss=9.49e-6, Validation Loss=8.68e-6, Best Loss=7.24e-6]
Training Fold 5: 40%|████ | 40/100 [00:21<00:31, 1.88 epochs/s, Training Loss=7.79e-6, Validation Loss=9.97e-6, Best Loss=7.24e-6]
Training Fold 5: 41%|████ | 41/100 [00:21<00:31, 1.88 epochs/s, Training Loss=7.79e-6, Validation Loss=9.97e-6, Best Loss=7.24e-6]
Training Fold 5: 41%|████ | 41/100 [00:21<00:31, 1.88 epochs/s, Training Loss=2.36e-5, Validation Loss=2.42e-5, Best Loss=7.24e-6]
Training Fold 5: 42%|████▏ | 42/100 [00:21<00:30, 1.89 epochs/s, Training Loss=2.36e-5, Validation Loss=2.42e-5, Best Loss=7.24e-6]
Training Fold 5: 42%|████▏ | 42/100 [00:22<00:30, 1.89 epochs/s, Training Loss=9.95e-6, Validation Loss=9.36e-6, Best Loss=7.24e-6]
Training Fold 5: 43%|████▎ | 43/100 [00:22<00:29, 1.90 epochs/s, Training Loss=9.95e-6, Validation Loss=9.36e-6, Best Loss=7.24e-6]
Training Fold 5: 43%|████▎ | 43/100 [00:22<00:29, 1.90 epochs/s, Training Loss=1.16e-5, Validation Loss=1.35e-5, Best Loss=7.24e-6]
Training Fold 5: 44%|████▍ | 44/100 [00:22<00:29, 1.90 epochs/s, Training Loss=1.16e-5, Validation Loss=1.35e-5, Best Loss=7.24e-6]
Training Fold 5: 44%|████▍ | 44/100 [00:23<00:29, 1.90 epochs/s, Training Loss=7.61e-6, Validation Loss=8.38e-6, Best Loss=7.24e-6]
Training Fold 5: 45%|████▌ | 45/100 [00:23<00:28, 1.92 epochs/s, Training Loss=7.61e-6, Validation Loss=8.38e-6, Best Loss=7.24e-6]
Training Fold 5: 45%|████▌ | 45/100 [00:23<00:28, 1.92 epochs/s, Training Loss=7.49e-6, Validation Loss=9.17e-6, Best Loss=7.24e-6]
Training Fold 5: 46%|████▌ | 46/100 [00:23<00:27, 1.93 epochs/s, Training Loss=7.49e-6, Validation Loss=9.17e-6, Best Loss=7.24e-6]
Training Fold 5: 46%|████▌ | 46/100 [00:24<00:27, 1.93 epochs/s, Training Loss=7.16e-6, Validation Loss=8.59e-6, Best Loss=7.24e-6]
Training Fold 5: 47%|████▋ | 47/100 [00:24<00:27, 1.92 epochs/s, Training Loss=7.16e-6, Validation Loss=8.59e-6, Best Loss=7.24e-6]
Training Fold 5: 47%|████▋ | 47/100 [00:24<00:27, 1.92 epochs/s, Training Loss=8.27e-6, Validation Loss=9.89e-6, Best Loss=7.24e-6]
Training Fold 5: 48%|████▊ | 48/100 [00:24<00:27, 1.91 epochs/s, Training Loss=8.27e-6, Validation Loss=9.89e-6, Best Loss=7.24e-6]
Training Fold 5: 48%|████▊ | 48/100 [00:25<00:27, 1.91 epochs/s, Training Loss=9.11e-6, Validation Loss=1.09e-5, Best Loss=7.24e-6]
Training Fold 5: 49%|████▉ | 49/100 [00:25<00:26, 1.96 epochs/s, Training Loss=9.11e-6, Validation Loss=1.09e-5, Best Loss=7.24e-6]
Training Fold 5: 49%|████▉ | 49/100 [00:25<00:26, 1.96 epochs/s, Training Loss=7.65e-6, Validation Loss=8.76e-6, Best Loss=7.24e-6]
Training Fold 5: 50%|█████ | 50/100 [00:25<00:25, 1.98 epochs/s, Training Loss=7.65e-6, Validation Loss=8.76e-6, Best Loss=7.24e-6]
Training Fold 5: 50%|█████ | 50/100 [00:26<00:25, 1.98 epochs/s, Training Loss=7.11e-6, Validation Loss=9.04e-6, Best Loss=7.24e-6]
Training Fold 5: 51%|█████ | 51/100 [00:26<00:25, 1.95 epochs/s, Training Loss=7.11e-6, Validation Loss=9.04e-6, Best Loss=7.24e-6]
Training Fold 5: 51%|█████ | 51/100 [00:26<00:25, 1.95 epochs/s, Training Loss=6.98e-6, Validation Loss=8.62e-6, Best Loss=7.24e-6]
Training Fold 5: 52%|█████▏ | 52/100 [00:26<00:24, 1.96 epochs/s, Training Loss=6.98e-6, Validation Loss=8.62e-6, Best Loss=7.24e-6]
Training Fold 5: 52%|█████▏ | 52/100 [00:27<00:24, 1.96 epochs/s, Training Loss=1.3e-5, Validation Loss=1.52e-5, Best Loss=7.24e-6]
Training Fold 5: 53%|█████▎ | 53/100 [00:27<00:24, 1.94 epochs/s, Training Loss=1.3e-5, Validation Loss=1.52e-5, Best Loss=7.24e-6]
Training Fold 5: 53%|█████▎ | 53/100 [00:27<00:24, 1.94 epochs/s, Training Loss=7.92e-6, Validation Loss=1.06e-5, Best Loss=7.24e-6]
Training Fold 5: 54%|█████▍ | 54/100 [00:27<00:23, 1.94 epochs/s, Training Loss=7.92e-6, Validation Loss=1.06e-5, Best Loss=7.24e-6]
Training Fold 5: 54%|█████▍ | 54/100 [00:28<00:23, 1.94 epochs/s, Training Loss=7.61e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 5: 55%|█████▌ | 55/100 [00:28<00:22, 1.96 epochs/s, Training Loss=7.61e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 5: 55%|█████▌ | 55/100 [00:28<00:22, 1.96 epochs/s, Training Loss=8.13e-6, Validation Loss=9.54e-6, Best Loss=7.24e-6]
Training Fold 5: 56%|█████▌ | 56/100 [00:28<00:22, 1.96 epochs/s, Training Loss=8.13e-6, Validation Loss=9.54e-6, Best Loss=7.24e-6]
Training Fold 5: 56%|█████▌ | 56/100 [00:29<00:22, 1.96 epochs/s, Training Loss=8.76e-6, Validation Loss=1.01e-5, Best Loss=7.24e-6]
Training Fold 5: 57%|█████▋ | 57/100 [00:29<00:22, 1.95 epochs/s, Training Loss=8.76e-6, Validation Loss=1.01e-5, Best Loss=7.24e-6]
Training Fold 5: 57%|█████▋ | 57/100 [00:29<00:22, 1.95 epochs/s, Training Loss=7.8e-6, Validation Loss=1.05e-5, Best Loss=7.24e-6]
Training Fold 5: 58%|█████▊ | 58/100 [00:29<00:22, 1.89 epochs/s, Training Loss=7.8e-6, Validation Loss=1.05e-5, Best Loss=7.24e-6]
Training Fold 5: 58%|█████▊ | 58/100 [00:30<00:22, 1.89 epochs/s, Training Loss=7.11e-6, Validation Loss=9.32e-6, Best Loss=7.24e-6]
Training Fold 5: 59%|█████▉ | 59/100 [00:30<00:27, 1.47 epochs/s, Training Loss=7.11e-6, Validation Loss=9.32e-6, Best Loss=7.24e-6]
Training Fold 5: 59%|█████▉ | 59/100 [00:31<00:27, 1.47 epochs/s, Training Loss=2.39e-5, Validation Loss=2.47e-5, Best Loss=7.24e-6]
Training Fold 5: 60%|██████ | 60/100 [00:31<00:25, 1.57 epochs/s, Training Loss=2.39e-5, Validation Loss=2.47e-5, Best Loss=7.24e-6]
Training Fold 5: 60%|██████ | 60/100 [00:32<00:25, 1.57 epochs/s, Training Loss=8.81e-6, Validation Loss=1.03e-5, Best Loss=7.24e-6]
Training Fold 5: 61%|██████ | 61/100 [00:32<00:24, 1.57 epochs/s, Training Loss=8.81e-6, Validation Loss=1.03e-5, Best Loss=7.24e-6]
Training Fold 5: 61%|██████ | 61/100 [00:32<00:24, 1.57 epochs/s, Training Loss=1.6e-5, Validation Loss=1.85e-5, Best Loss=7.24e-6]
Training Fold 5: 62%|██████▏ | 62/100 [00:32<00:23, 1.61 epochs/s, Training Loss=1.6e-5, Validation Loss=1.85e-5, Best Loss=7.24e-6]
Training Fold 5: 62%|██████▏ | 62/100 [00:33<00:23, 1.61 epochs/s, Training Loss=7.74e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 5: 63%|██████▎ | 63/100 [00:33<00:23, 1.57 epochs/s, Training Loss=7.74e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 5: 63%|██████▎ | 63/100 [00:34<00:23, 1.57 epochs/s, Training Loss=7.48e-6, Validation Loss=9.38e-6, Best Loss=7.24e-6]
Training Fold 5: 64%|██████▍ | 64/100 [00:34<00:25, 1.43 epochs/s, Training Loss=7.48e-6, Validation Loss=9.38e-6, Best Loss=7.24e-6]
Training Fold 5: 64%|██████▍ | 64/100 [00:34<00:25, 1.43 epochs/s, Training Loss=7.58e-6, Validation Loss=9.2e-6, Best Loss=7.24e-6]
Training Fold 5: 65%|██████▌ | 65/100 [00:34<00:23, 1.51 epochs/s, Training Loss=7.58e-6, Validation Loss=9.2e-6, Best Loss=7.24e-6]
Training Fold 5: 65%|██████▌ | 65/100 [00:35<00:23, 1.51 epochs/s, Training Loss=7.16e-6, Validation Loss=9.26e-6, Best Loss=7.24e-6]
Training Fold 5: 66%|██████▌ | 66/100 [00:35<00:21, 1.60 epochs/s, Training Loss=7.16e-6, Validation Loss=9.26e-6, Best Loss=7.24e-6]
Training Fold 5: 66%|██████▌ | 66/100 [00:36<00:21, 1.60 epochs/s, Training Loss=6.52e-6, Validation Loss=8.16e-6, Best Loss=7.24e-6]
Training Fold 5: 67%|██████▋ | 67/100 [00:36<00:23, 1.41 epochs/s, Training Loss=6.52e-6, Validation Loss=8.16e-6, Best Loss=7.24e-6]
Training Fold 5: 67%|██████▋ | 67/100 [00:37<00:23, 1.41 epochs/s, Training Loss=9.04e-6, Validation Loss=1.28e-5, Best Loss=7.24e-6]
Training Fold 5: 68%|██████▊ | 68/100 [00:37<00:26, 1.23 epochs/s, Training Loss=9.04e-6, Validation Loss=1.28e-5, Best Loss=7.24e-6]
Training Fold 5: 68%|██████▊ | 68/100 [00:37<00:26, 1.23 epochs/s, Training Loss=7.14e-6, Validation Loss=9.34e-6, Best Loss=7.24e-6]
Training Fold 5: 69%|██████▉ | 69/100 [00:37<00:22, 1.36 epochs/s, Training Loss=7.14e-6, Validation Loss=9.34e-6, Best Loss=7.24e-6]
Training Fold 5: 69%|██████▉ | 69/100 [00:38<00:22, 1.36 epochs/s, Training Loss=7.44e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 5: 70%|███████ | 70/100 [00:38<00:20, 1.46 epochs/s, Training Loss=7.44e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 5: 70%|███████ | 70/100 [00:38<00:20, 1.46 epochs/s, Training Loss=6.97e-6, Validation Loss=8.86e-6, Best Loss=7.24e-6]
Training Fold 5: 71%|███████ | 71/100 [00:38<00:19, 1.52 epochs/s, Training Loss=6.97e-6, Validation Loss=8.86e-6, Best Loss=7.24e-6]
Training Fold 5: 71%|███████ | 71/100 [00:39<00:19, 1.52 epochs/s, Training Loss=1.19e-5, Validation Loss=1.53e-5, Best Loss=7.24e-6]
Training Fold 5: 72%|███████▏ | 72/100 [00:39<00:19, 1.44 epochs/s, Training Loss=1.19e-5, Validation Loss=1.53e-5, Best Loss=7.24e-6]
Training Fold 5: 72%|███████▏ | 72/100 [00:40<00:19, 1.44 epochs/s, Training Loss=7.19e-6, Validation Loss=9.23e-6, Best Loss=7.24e-6]
Training Fold 5: 73%|███████▎ | 73/100 [00:40<00:18, 1.46 epochs/s, Training Loss=7.19e-6, Validation Loss=9.23e-6, Best Loss=7.24e-6]
Training Fold 5: 73%|███████▎ | 73/100 [00:41<00:18, 1.46 epochs/s, Training Loss=6.52e-6, Validation Loss=8.92e-6, Best Loss=7.24e-6]
Training Fold 5: 74%|███████▍ | 74/100 [00:41<00:18, 1.39 epochs/s, Training Loss=6.52e-6, Validation Loss=8.92e-6, Best Loss=7.24e-6]
Training Fold 5: 74%|███████▍ | 74/100 [00:41<00:18, 1.39 epochs/s, Training Loss=6.34e-6, Validation Loss=8.9e-6, Best Loss=7.24e-6]
Training Fold 5: 75%|███████▌ | 75/100 [00:41<00:17, 1.47 epochs/s, Training Loss=6.34e-6, Validation Loss=8.9e-6, Best Loss=7.24e-6]
Training Fold 5: 75%|███████▌ | 75/100 [00:42<00:17, 1.47 epochs/s, Training Loss=8e-6, Validation Loss=9.99e-6, Best Loss=7.24e-6]
Training Fold 5: 76%|███████▌ | 76/100 [00:42<00:15, 1.54 epochs/s, Training Loss=8e-6, Validation Loss=9.99e-6, Best Loss=7.24e-6]
Training Fold 5: 76%|███████▌ | 76/100 [00:42<00:15, 1.54 epochs/s, Training Loss=1.03e-5, Validation Loss=1.19e-5, Best Loss=7.24e-6]
Training Fold 5: 77%|███████▋ | 77/100 [00:42<00:14, 1.59 epochs/s, Training Loss=1.03e-5, Validation Loss=1.19e-5, Best Loss=7.24e-6]
Training Fold 5: 77%|███████▋ | 77/100 [00:43<00:14, 1.59 epochs/s, Training Loss=8.13e-6, Validation Loss=1.02e-5, Best Loss=7.24e-6]
Training Fold 5: 78%|███████▊ | 78/100 [00:43<00:13, 1.67 epochs/s, Training Loss=8.13e-6, Validation Loss=1.02e-5, Best Loss=7.24e-6]
Training Fold 5: 78%|███████▊ | 78/100 [00:44<00:13, 1.67 epochs/s, Training Loss=8.52e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 5: 79%|███████▉ | 79/100 [00:44<00:12, 1.69 epochs/s, Training Loss=8.52e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 5: 79%|███████▉ | 79/100 [00:44<00:12, 1.69 epochs/s, Training Loss=7.1e-6, Validation Loss=8.58e-6, Best Loss=7.24e-6]
Training Fold 5: 80%|████████ | 80/100 [00:44<00:11, 1.74 epochs/s, Training Loss=7.1e-6, Validation Loss=8.58e-6, Best Loss=7.24e-6]
Training Fold 5: 80%|████████ | 80/100 [00:45<00:11, 1.74 epochs/s, Training Loss=6.81e-6, Validation Loss=9.23e-6, Best Loss=7.24e-6]
Training Fold 5: 81%|████████ | 81/100 [00:45<00:10, 1.77 epochs/s, Training Loss=6.81e-6, Validation Loss=9.23e-6, Best Loss=7.24e-6]
Training Fold 5: 81%|████████ | 81/100 [00:45<00:10, 1.77 epochs/s, Training Loss=6.79e-6, Validation Loss=9.37e-6, Best Loss=7.24e-6]
Training Fold 5: 82%|████████▏ | 82/100 [00:45<00:10, 1.76 epochs/s, Training Loss=6.79e-6, Validation Loss=9.37e-6, Best Loss=7.24e-6]
Training Fold 5: 82%|████████▏ | 82/100 [00:46<00:10, 1.76 epochs/s, Training Loss=6.82e-6, Validation Loss=8.77e-6, Best Loss=7.24e-6]
Training Fold 5: 83%|████████▎ | 83/100 [00:46<00:09, 1.72 epochs/s, Training Loss=6.82e-6, Validation Loss=8.77e-6, Best Loss=7.24e-6]
Training Fold 5: 83%|████████▎ | 83/100 [00:46<00:09, 1.72 epochs/s, Training Loss=8.9e-6, Validation Loss=9.54e-6, Best Loss=7.24e-6]
Training Fold 5: 84%|████████▍ | 84/100 [00:46<00:09, 1.77 epochs/s, Training Loss=8.9e-6, Validation Loss=9.54e-6, Best Loss=7.24e-6]
Training Fold 5: 84%|████████▍ | 84/100 [00:47<00:09, 1.77 epochs/s, Training Loss=1e-5, Validation Loss=1.13e-5, Best Loss=7.24e-6]
Training Fold 5: 85%|████████▌ | 85/100 [00:47<00:08, 1.80 epochs/s, Training Loss=1e-5, Validation Loss=1.13e-5, Best Loss=7.24e-6]
Training Fold 5: 85%|████████▌ | 85/100 [00:47<00:08, 1.80 epochs/s, Training Loss=8.05e-6, Validation Loss=1.17e-5, Best Loss=7.24e-6]
Training Fold 5: 86%|████████▌ | 86/100 [00:47<00:07, 1.82 epochs/s, Training Loss=8.05e-6, Validation Loss=1.17e-5, Best Loss=7.24e-6]
Training Fold 5: 86%|████████▌ | 86/100 [00:48<00:07, 1.82 epochs/s, Training Loss=7.36e-6, Validation Loss=9.45e-6, Best Loss=7.24e-6]
Training Fold 5: 87%|████████▋ | 87/100 [00:48<00:07, 1.81 epochs/s, Training Loss=7.36e-6, Validation Loss=9.45e-6, Best Loss=7.24e-6]
Training Fold 5: 87%|████████▋ | 87/100 [00:48<00:07, 1.81 epochs/s, Training Loss=6.86e-6, Validation Loss=7.97e-6, Best Loss=7.24e-6]
Training Fold 5: 88%|████████▊ | 88/100 [00:48<00:06, 1.84 epochs/s, Training Loss=6.86e-6, Validation Loss=7.97e-6, Best Loss=7.24e-6]
Training Fold 5: 88%|████████▊ | 88/100 [00:49<00:06, 1.84 epochs/s, Training Loss=6.92e-6, Validation Loss=8.43e-6, Best Loss=7.24e-6]
Training Fold 5: 89%|████████▉ | 89/100 [00:49<00:05, 1.85 epochs/s, Training Loss=6.92e-6, Validation Loss=8.43e-6, Best Loss=7.24e-6]
Training Fold 5: 89%|████████▉ | 89/100 [00:50<00:05, 1.85 epochs/s, Training Loss=6.24e-6, Validation Loss=8.17e-6, Best Loss=7.24e-6]
Training Fold 5: 90%|█████████ | 90/100 [00:50<00:05, 1.86 epochs/s, Training Loss=6.24e-6, Validation Loss=8.17e-6, Best Loss=7.24e-6]
Training Fold 5: 90%|█████████ | 90/100 [00:50<00:05, 1.86 epochs/s, Training Loss=1.28e-5, Validation Loss=1.3e-5, Best Loss=7.24e-6]
Training Fold 5: 91%|█████████ | 91/100 [00:50<00:04, 1.85 epochs/s, Training Loss=1.28e-5, Validation Loss=1.3e-5, Best Loss=7.24e-6]
Training Fold 5: 91%|█████████ | 91/100 [00:51<00:04, 1.85 epochs/s, Training Loss=6.41e-6, Validation Loss=8.02e-6, Best Loss=7.24e-6]
Training Fold 5: 92%|█████████▏| 92/100 [00:51<00:04, 1.87 epochs/s, Training Loss=6.41e-6, Validation Loss=8.02e-6, Best Loss=7.24e-6]
Training Fold 5: 92%|█████████▏| 92/100 [00:51<00:04, 1.87 epochs/s, Training Loss=6.85e-6, Validation Loss=9.05e-6, Best Loss=7.24e-6]
Training Fold 5: 93%|█████████▎| 93/100 [00:51<00:03, 1.89 epochs/s, Training Loss=6.85e-6, Validation Loss=9.05e-6, Best Loss=7.24e-6]
Training Fold 5: 93%|█████████▎| 93/100 [00:52<00:03, 1.89 epochs/s, Training Loss=1.05e-5, Validation Loss=1.37e-5, Best Loss=7.24e-6]
Training Fold 5: 94%|█████████▍| 94/100 [00:52<00:03, 1.89 epochs/s, Training Loss=1.05e-5, Validation Loss=1.37e-5, Best Loss=7.24e-6]
Training Fold 5: 94%|█████████▍| 94/100 [00:52<00:03, 1.89 epochs/s, Training Loss=7.39e-6, Validation Loss=9.88e-6, Best Loss=7.24e-6]
Training Fold 5: 95%|█████████▌| 95/100 [00:52<00:02, 1.92 epochs/s, Training Loss=7.39e-6, Validation Loss=9.88e-6, Best Loss=7.24e-6]
Training Fold 5: 95%|█████████▌| 95/100 [00:53<00:02, 1.92 epochs/s, Training Loss=6.25e-6, Validation Loss=8.82e-6, Best Loss=7.24e-6]
Training Fold 5: 96%|█████████▌| 96/100 [00:53<00:02, 1.92 epochs/s, Training Loss=6.25e-6, Validation Loss=8.82e-6, Best Loss=7.24e-6]
Training Fold 5: 96%|█████████▌| 96/100 [00:53<00:02, 1.92 epochs/s, Training Loss=6.87e-6, Validation Loss=9.02e-6, Best Loss=7.24e-6]
Training Fold 5: 97%|█████████▋| 97/100 [00:53<00:01, 1.90 epochs/s, Training Loss=6.87e-6, Validation Loss=9.02e-6, Best Loss=7.24e-6]
Training Fold 5: 97%|█████████▋| 97/100 [00:54<00:01, 1.90 epochs/s, Training Loss=6.77e-6, Validation Loss=8.52e-6, Best Loss=7.24e-6]
Training Fold 5: 98%|█████████▊| 98/100 [00:54<00:01, 1.88 epochs/s, Training Loss=6.77e-6, Validation Loss=8.52e-6, Best Loss=7.24e-6]
Training Fold 5: 98%|█████████▊| 98/100 [00:54<00:01, 1.88 epochs/s, Training Loss=6.85e-6, Validation Loss=9.12e-6, Best Loss=7.24e-6]
Training Fold 5: 99%|█████████▉| 99/100 [00:54<00:00, 1.86 epochs/s, Training Loss=6.85e-6, Validation Loss=9.12e-6, Best Loss=7.24e-6]
Training Fold 5: 99%|█████████▉| 99/100 [00:55<00:00, 1.86 epochs/s, Training Loss=1.74e-5, Validation Loss=1.97e-5, Best Loss=7.24e-6]
Training Fold 5: 100%|██████████| 100/100 [00:55<00:00, 1.89 epochs/s, Training Loss=1.74e-5, Validation Loss=1.97e-5, Best Loss=7.24e-6]
Training Fold 5: 100%|██████████| 100/100 [00:55<00:00, 1.81 epochs/s, Training Loss=1.74e-5, Validation Loss=1.97e-5, Best Loss=7.24e-6]
0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 6: 0%| | 0/100 [00:00<?, ? epochs/s]
Training Fold 6: 0%| | 0/100 [00:00<?, ? epochs/s, Training Loss=1.07e-5, Validation Loss=1.18e-5, Best Loss=7.24e-6]
Training Fold 6: 1%| | 1/100 [00:00<00:49, 2.00 epochs/s, Training Loss=1.07e-5, Validation Loss=1.18e-5, Best Loss=7.24e-6]
Training Fold 6: 1%| | 1/100 [00:01<00:49, 2.00 epochs/s, Training Loss=7.08e-6, Validation Loss=8.08e-6, Best Loss=7.24e-6]
Training Fold 6: 2%|▏ | 2/100 [00:01<00:51, 1.91 epochs/s, Training Loss=7.08e-6, Validation Loss=8.08e-6, Best Loss=7.24e-6]
Training Fold 6: 2%|▏ | 2/100 [00:01<00:51, 1.91 epochs/s, Training Loss=1.68e-5, Validation Loss=1.87e-5, Best Loss=7.24e-6]
Training Fold 6: 3%|▎ | 3/100 [00:01<00:51, 1.89 epochs/s, Training Loss=1.68e-5, Validation Loss=1.87e-5, Best Loss=7.24e-6]
Training Fold 6: 3%|▎ | 3/100 [00:02<00:51, 1.89 epochs/s, Training Loss=8.33e-6, Validation Loss=8.25e-6, Best Loss=7.24e-6]
Training Fold 6: 4%|▍ | 4/100 [00:02<00:50, 1.92 epochs/s, Training Loss=8.33e-6, Validation Loss=8.25e-6, Best Loss=7.24e-6]
Training Fold 6: 4%|▍ | 4/100 [00:02<00:50, 1.92 epochs/s, Training Loss=5.96e-6, Validation Loss=7.35e-6, Best Loss=7.24e-6]
Training Fold 6: 5%|▌ | 5/100 [00:02<00:50, 1.88 epochs/s, Training Loss=5.96e-6, Validation Loss=7.35e-6, Best Loss=7.24e-6]
Training Fold 6: 5%|▌ | 5/100 [00:03<00:50, 1.88 epochs/s, Training Loss=1.17e-5, Validation Loss=1.33e-5, Best Loss=7.24e-6]
Training Fold 6: 6%|▌ | 6/100 [00:03<00:50, 1.86 epochs/s, Training Loss=1.17e-5, Validation Loss=1.33e-5, Best Loss=7.24e-6]
Training Fold 6: 6%|▌ | 6/100 [00:03<00:50, 1.86 epochs/s, Training Loss=6.22e-6, Validation Loss=7.69e-6, Best Loss=7.24e-6]
Training Fold 6: 7%|▋ | 7/100 [00:03<00:51, 1.82 epochs/s, Training Loss=6.22e-6, Validation Loss=7.69e-6, Best Loss=7.24e-6]
Training Fold 6: 7%|▋ | 7/100 [00:04<00:51, 1.82 epochs/s, Training Loss=8.88e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 6: 8%|▊ | 8/100 [00:04<00:49, 1.84 epochs/s, Training Loss=8.88e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 6: 8%|▊ | 8/100 [00:04<00:49, 1.84 epochs/s, Training Loss=1.09e-5, Validation Loss=1.2e-5, Best Loss=7.24e-6]
Training Fold 6: 9%|▉ | 9/100 [00:04<00:51, 1.76 epochs/s, Training Loss=1.09e-5, Validation Loss=1.2e-5, Best Loss=7.24e-6]
Training Fold 6: 9%|▉ | 9/100 [00:05<00:51, 1.76 epochs/s, Training Loss=6.38e-6, Validation Loss=8.21e-6, Best Loss=7.24e-6]
Training Fold 6: 10%|█ | 10/100 [00:05<00:55, 1.62 epochs/s, Training Loss=6.38e-6, Validation Loss=8.21e-6, Best Loss=7.24e-6]
Training Fold 6: 10%|█ | 10/100 [00:06<00:55, 1.62 epochs/s, Training Loss=6.74e-6, Validation Loss=8.2e-6, Best Loss=7.24e-6]
Training Fold 6: 11%|█ | 11/100 [00:06<00:56, 1.56 epochs/s, Training Loss=6.74e-6, Validation Loss=8.2e-6, Best Loss=7.24e-6]
Training Fold 6: 11%|█ | 11/100 [00:06<00:56, 1.56 epochs/s, Training Loss=6.64e-6, Validation Loss=8.74e-6, Best Loss=7.24e-6]
Training Fold 6: 12%|█▏ | 12/100 [00:06<00:55, 1.59 epochs/s, Training Loss=6.64e-6, Validation Loss=8.74e-6, Best Loss=7.24e-6]
Training Fold 6: 12%|█▏ | 12/100 [00:07<00:55, 1.59 epochs/s, Training Loss=6.53e-6, Validation Loss=8.71e-6, Best Loss=7.24e-6]
Training Fold 6: 13%|█▎ | 13/100 [00:07<00:52, 1.66 epochs/s, Training Loss=6.53e-6, Validation Loss=8.71e-6, Best Loss=7.24e-6]
Training Fold 6: 13%|█▎ | 13/100 [00:08<00:52, 1.66 epochs/s, Training Loss=6.6e-6, Validation Loss=8.31e-6, Best Loss=7.24e-6]
Training Fold 6: 14%|█▍ | 14/100 [00:08<00:51, 1.68 epochs/s, Training Loss=6.6e-6, Validation Loss=8.31e-6, Best Loss=7.24e-6]
Training Fold 6: 14%|█▍ | 14/100 [00:08<00:51, 1.68 epochs/s, Training Loss=8.25e-6, Validation Loss=9.19e-6, Best Loss=7.24e-6]
Training Fold 6: 15%|█▌ | 15/100 [00:08<00:49, 1.73 epochs/s, Training Loss=8.25e-6, Validation Loss=9.19e-6, Best Loss=7.24e-6]
Training Fold 6: 15%|█▌ | 15/100 [00:09<00:49, 1.73 epochs/s, Training Loss=6.87e-6, Validation Loss=8.75e-6, Best Loss=7.24e-6]
Training Fold 6: 16%|█▌ | 16/100 [00:09<00:49, 1.71 epochs/s, Training Loss=6.87e-6, Validation Loss=8.75e-6, Best Loss=7.24e-6]
Training Fold 6: 16%|█▌ | 16/100 [00:09<00:49, 1.71 epochs/s, Training Loss=7.41e-6, Validation Loss=9.36e-6, Best Loss=7.24e-6]
Training Fold 6: 17%|█▋ | 17/100 [00:09<00:47, 1.75 epochs/s, Training Loss=7.41e-6, Validation Loss=9.36e-6, Best Loss=7.24e-6]
Training Fold 6: 17%|█▋ | 17/100 [00:10<00:47, 1.75 epochs/s, Training Loss=5.91e-6, Validation Loss=7.76e-6, Best Loss=7.24e-6]
Training Fold 6: 18%|█▊ | 18/100 [00:10<00:46, 1.76 epochs/s, Training Loss=5.91e-6, Validation Loss=7.76e-6, Best Loss=7.24e-6]
Training Fold 6: 18%|█▊ | 18/100 [00:10<00:46, 1.76 epochs/s, Training Loss=9.79e-6, Validation Loss=9.44e-6, Best Loss=7.24e-6]
Training Fold 6: 19%|█▉ | 19/100 [00:10<00:46, 1.75 epochs/s, Training Loss=9.79e-6, Validation Loss=9.44e-6, Best Loss=7.24e-6]
Training Fold 6: 19%|█▉ | 19/100 [00:11<00:46, 1.75 epochs/s, Training Loss=6.6e-6, Validation Loss=8.47e-6, Best Loss=7.24e-6]
Training Fold 6: 20%|██ | 20/100 [00:11<00:45, 1.77 epochs/s, Training Loss=6.6e-6, Validation Loss=8.47e-6, Best Loss=7.24e-6]
Training Fold 6: 20%|██ | 20/100 [00:11<00:45, 1.77 epochs/s, Training Loss=6.5e-6, Validation Loss=8.64e-6, Best Loss=7.24e-6]
Training Fold 6: 21%|██ | 21/100 [00:11<00:44, 1.79 epochs/s, Training Loss=6.5e-6, Validation Loss=8.64e-6, Best Loss=7.24e-6]
Training Fold 6: 21%|██ | 21/100 [00:12<00:44, 1.79 epochs/s, Training Loss=5.78e-6, Validation Loss=8.06e-6, Best Loss=7.24e-6]
Training Fold 6: 22%|██▏ | 22/100 [00:12<00:43, 1.78 epochs/s, Training Loss=5.78e-6, Validation Loss=8.06e-6, Best Loss=7.24e-6]
Training Fold 6: 22%|██▏ | 22/100 [00:13<00:43, 1.78 epochs/s, Training Loss=5.87e-6, Validation Loss=8.04e-6, Best Loss=7.24e-6]
Training Fold 6: 23%|██▎ | 23/100 [00:13<00:43, 1.76 epochs/s, Training Loss=5.87e-6, Validation Loss=8.04e-6, Best Loss=7.24e-6]
Training Fold 6: 23%|██▎ | 23/100 [00:13<00:43, 1.76 epochs/s, Training Loss=9.16e-6, Validation Loss=1.12e-5, Best Loss=7.24e-6]
Training Fold 6: 24%|██▍ | 24/100 [00:13<00:43, 1.75 epochs/s, Training Loss=9.16e-6, Validation Loss=1.12e-5, Best Loss=7.24e-6]
Training Fold 6: 24%|██▍ | 24/100 [00:14<00:43, 1.75 epochs/s, Training Loss=5.84e-6, Validation Loss=7.96e-6, Best Loss=7.24e-6]
Training Fold 6: 25%|██▌ | 25/100 [00:14<00:41, 1.80 epochs/s, Training Loss=5.84e-6, Validation Loss=7.96e-6, Best Loss=7.24e-6]
Training Fold 6: 25%|██▌ | 25/100 [00:14<00:41, 1.80 epochs/s, Training Loss=6.36e-6, Validation Loss=8.4e-6, Best Loss=7.24e-6]
Training Fold 6: 26%|██▌ | 26/100 [00:14<00:41, 1.78 epochs/s, Training Loss=6.36e-6, Validation Loss=8.4e-6, Best Loss=7.24e-6]
Training Fold 6: 26%|██▌ | 26/100 [00:15<00:41, 1.78 epochs/s, Training Loss=6.32e-6, Validation Loss=7.95e-6, Best Loss=7.24e-6]
Training Fold 6: 27%|██▋ | 27/100 [00:15<00:46, 1.57 epochs/s, Training Loss=6.32e-6, Validation Loss=7.95e-6, Best Loss=7.24e-6]
Training Fold 6: 27%|██▋ | 27/100 [00:16<00:46, 1.57 epochs/s, Training Loss=2.04e-5, Validation Loss=2.2e-5, Best Loss=7.24e-6]
Training Fold 6: 28%|██▊ | 28/100 [00:16<00:43, 1.64 epochs/s, Training Loss=2.04e-5, Validation Loss=2.2e-5, Best Loss=7.24e-6]
Training Fold 6: 28%|██▊ | 28/100 [00:16<00:43, 1.64 epochs/s, Training Loss=1.12e-5, Validation Loss=1.34e-5, Best Loss=7.24e-6]
Training Fold 6: 29%|██▉ | 29/100 [00:16<00:42, 1.67 epochs/s, Training Loss=1.12e-5, Validation Loss=1.34e-5, Best Loss=7.24e-6]
Training Fold 6: 29%|██▉ | 29/100 [00:17<00:42, 1.67 epochs/s, Training Loss=7.75e-6, Validation Loss=9.71e-6, Best Loss=7.24e-6]
Training Fold 6: 30%|███ | 30/100 [00:17<00:42, 1.66 epochs/s, Training Loss=7.75e-6, Validation Loss=9.71e-6, Best Loss=7.24e-6]
Training Fold 6: 30%|███ | 30/100 [00:17<00:42, 1.66 epochs/s, Training Loss=6.85e-6, Validation Loss=9.16e-6, Best Loss=7.24e-6]
Training Fold 6: 31%|███ | 31/100 [00:17<00:41, 1.66 epochs/s, Training Loss=6.85e-6, Validation Loss=9.16e-6, Best Loss=7.24e-6]
Training Fold 6: 31%|███ | 31/100 [00:18<00:41, 1.66 epochs/s, Training Loss=8.39e-6, Validation Loss=9.66e-6, Best Loss=7.24e-6]
Training Fold 6: 32%|███▏ | 32/100 [00:18<00:40, 1.67 epochs/s, Training Loss=8.39e-6, Validation Loss=9.66e-6, Best Loss=7.24e-6]
Training Fold 6: 32%|███▏ | 32/100 [00:19<00:40, 1.67 epochs/s, Training Loss=6.42e-6, Validation Loss=8.27e-6, Best Loss=7.24e-6]
Training Fold 6: 33%|███▎ | 33/100 [00:19<00:40, 1.66 epochs/s, Training Loss=6.42e-6, Validation Loss=8.27e-6, Best Loss=7.24e-6]
Training Fold 6: 33%|███▎ | 33/100 [00:19<00:40, 1.66 epochs/s, Training Loss=6.17e-6, Validation Loss=8.64e-6, Best Loss=7.24e-6]
Training Fold 6: 34%|███▍ | 34/100 [00:19<00:39, 1.67 epochs/s, Training Loss=6.17e-6, Validation Loss=8.64e-6, Best Loss=7.24e-6]
Training Fold 6: 34%|███▍ | 34/100 [00:20<00:39, 1.67 epochs/s, Training Loss=5.89e-6, Validation Loss=8.32e-6, Best Loss=7.24e-6]
Training Fold 6: 35%|███▌ | 35/100 [00:20<00:40, 1.61 epochs/s, Training Loss=5.89e-6, Validation Loss=8.32e-6, Best Loss=7.24e-6]
Training Fold 6: 35%|███▌ | 35/100 [00:21<00:40, 1.61 epochs/s, Training Loss=7e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 6: 36%|███▌ | 36/100 [00:21<00:39, 1.62 epochs/s, Training Loss=7e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 6: 36%|███▌ | 36/100 [00:21<00:39, 1.62 epochs/s, Training Loss=6.83e-6, Validation Loss=9.06e-6, Best Loss=7.24e-6]
Training Fold 6: 37%|███▋ | 37/100 [00:21<00:39, 1.59 epochs/s, Training Loss=6.83e-6, Validation Loss=9.06e-6, Best Loss=7.24e-6]
Training Fold 6: 37%|███▋ | 37/100 [00:22<00:39, 1.59 epochs/s, Training Loss=6.22e-6, Validation Loss=8.91e-6, Best Loss=7.24e-6]
Training Fold 6: 38%|███▊ | 38/100 [00:22<00:38, 1.63 epochs/s, Training Loss=6.22e-6, Validation Loss=8.91e-6, Best Loss=7.24e-6]
Training Fold 6: 38%|███▊ | 38/100 [00:22<00:38, 1.63 epochs/s, Training Loss=9.55e-6, Validation Loss=1.16e-5, Best Loss=7.24e-6]
Training Fold 6: 39%|███▉ | 39/100 [00:22<00:36, 1.66 epochs/s, Training Loss=9.55e-6, Validation Loss=1.16e-5, Best Loss=7.24e-6]
Training Fold 6: 39%|███▉ | 39/100 [00:23<00:36, 1.66 epochs/s, Training Loss=6.11e-6, Validation Loss=8.45e-6, Best Loss=7.24e-6]
Training Fold 6: 40%|████ | 40/100 [00:23<00:36, 1.66 epochs/s, Training Loss=6.11e-6, Validation Loss=8.45e-6, Best Loss=7.24e-6]
Training Fold 6: 40%|████ | 40/100 [00:24<00:36, 1.66 epochs/s, Training Loss=5.59e-6, Validation Loss=8.36e-6, Best Loss=7.24e-6]
Training Fold 6: 41%|████ | 41/100 [00:24<00:35, 1.65 epochs/s, Training Loss=5.59e-6, Validation Loss=8.36e-6, Best Loss=7.24e-6]
Training Fold 6: 41%|████ | 41/100 [00:24<00:35, 1.65 epochs/s, Training Loss=9.16e-6, Validation Loss=1.08e-5, Best Loss=7.24e-6]
Training Fold 6: 42%|████▏ | 42/100 [00:24<00:34, 1.67 epochs/s, Training Loss=9.16e-6, Validation Loss=1.08e-5, Best Loss=7.24e-6]
Training Fold 6: 42%|████▏ | 42/100 [00:25<00:34, 1.67 epochs/s, Training Loss=7.59e-6, Validation Loss=9.53e-6, Best Loss=7.24e-6]
Training Fold 6: 43%|████▎ | 43/100 [00:25<00:34, 1.66 epochs/s, Training Loss=7.59e-6, Validation Loss=9.53e-6, Best Loss=7.24e-6]
Training Fold 6: 43%|████▎ | 43/100 [00:25<00:34, 1.66 epochs/s, Training Loss=6.32e-6, Validation Loss=8.95e-6, Best Loss=7.24e-6]
Training Fold 6: 44%|████▍ | 44/100 [00:25<00:33, 1.66 epochs/s, Training Loss=6.32e-6, Validation Loss=8.95e-6, Best Loss=7.24e-6]
Training Fold 6: 44%|████▍ | 44/100 [00:26<00:33, 1.66 epochs/s, Training Loss=7.02e-6, Validation Loss=9.85e-6, Best Loss=7.24e-6]
Training Fold 6: 45%|████▌ | 45/100 [00:26<00:33, 1.64 epochs/s, Training Loss=7.02e-6, Validation Loss=9.85e-6, Best Loss=7.24e-6]
Training Fold 6: 45%|████▌ | 45/100 [00:27<00:33, 1.64 epochs/s, Training Loss=7.31e-6, Validation Loss=8.6e-6, Best Loss=7.24e-6]
Training Fold 6: 46%|████▌ | 46/100 [00:27<00:32, 1.66 epochs/s, Training Loss=7.31e-6, Validation Loss=8.6e-6, Best Loss=7.24e-6]
Training Fold 6: 46%|████▌ | 46/100 [00:27<00:32, 1.66 epochs/s, Training Loss=6.83e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 6: 47%|████▋ | 47/100 [00:27<00:31, 1.68 epochs/s, Training Loss=6.83e-6, Validation Loss=1e-5, Best Loss=7.24e-6]
Training Fold 6: 47%|████▋ | 47/100 [00:28<00:31, 1.68 epochs/s, Training Loss=7.19e-6, Validation Loss=1.02e-5, Best Loss=7.24e-6]
Training Fold 6: 48%|████▊ | 48/100 [00:28<00:31, 1.67 epochs/s, Training Loss=7.19e-6, Validation Loss=1.02e-5, Best Loss=7.24e-6]
Training Fold 6: 48%|████▊ | 48/100 [00:28<00:31, 1.67 epochs/s, Training Loss=5.49e-6, Validation Loss=8.1e-6, Best Loss=7.24e-6]
Training Fold 6: 49%|████▉ | 49/100 [00:28<00:30, 1.70 epochs/s, Training Loss=5.49e-6, Validation Loss=8.1e-6, Best Loss=7.24e-6]
Training Fold 6: 49%|████▉ | 49/100 [00:29<00:30, 1.70 epochs/s, Training Loss=5.83e-6, Validation Loss=8.25e-6, Best Loss=7.24e-6]
Training Fold 6: 50%|█████ | 50/100 [00:29<00:29, 1.69 epochs/s, Training Loss=5.83e-6, Validation Loss=8.25e-6, Best Loss=7.24e-6]
Training Fold 6: 50%|█████ | 50/100 [00:29<00:29, 1.69 epochs/s, Training Loss=6.45e-6, Validation Loss=9.22e-6, Best Loss=7.24e-6]
Training Fold 6: 51%|█████ | 51/100 [00:29<00:28, 1.70 epochs/s, Training Loss=6.45e-6, Validation Loss=9.22e-6, Best Loss=7.24e-6]
Training Fold 6: 51%|█████ | 51/100 [00:30<00:28, 1.70 epochs/s, Training Loss=6.07e-6, Validation Loss=9.15e-6, Best Loss=7.24e-6]
Training Fold 6: 52%|█████▏ | 52/100 [00:30<00:28, 1.70 epochs/s, Training Loss=6.07e-6, Validation Loss=9.15e-6, Best Loss=7.24e-6]
Training Fold 6: 52%|█████▏ | 52/100 [00:31<00:28, 1.70 epochs/s, Training Loss=5.95e-6, Validation Loss=8.98e-6, Best Loss=7.24e-6]
Training Fold 6: 53%|█████▎ | 53/100 [00:31<00:28, 1.68 epochs/s, Training Loss=5.95e-6, Validation Loss=8.98e-6, Best Loss=7.24e-6]
Training Fold 6: 53%|█████▎ | 53/100 [00:31<00:28, 1.68 epochs/s, Training Loss=6.58e-6, Validation Loss=8.67e-6, Best Loss=7.24e-6]
Training Fold 6: 54%|█████▍ | 54/100 [00:31<00:27, 1.67 epochs/s, Training Loss=6.58e-6, Validation Loss=8.67e-6, Best Loss=7.24e-6]
Training Fold 6: 54%|█████▍ | 54/100 [00:32<00:27, 1.67 epochs/s, Training Loss=5.99e-6, Validation Loss=8.7e-6, Best Loss=7.24e-6]
Training Fold 6: 55%|█████▌ | 55/100 [00:32<00:27, 1.66 epochs/s, Training Loss=5.99e-6, Validation Loss=8.7e-6, Best Loss=7.24e-6]
Training Fold 6: 55%|█████▌ | 55/100 [00:32<00:27, 1.66 epochs/s, Training Loss=1.51e-5, Validation Loss=1.6e-5, Best Loss=7.24e-6]
Training Fold 6: 56%|█████▌ | 56/100 [00:32<00:26, 1.68 epochs/s, Training Loss=1.51e-5, Validation Loss=1.6e-5, Best Loss=7.24e-6]
Training Fold 6: 56%|█████▌ | 56/100 [00:33<00:26, 1.68 epochs/s, Training Loss=7.95e-6, Validation Loss=1.07e-5, Best Loss=7.24e-6]
Training Fold 6: 57%|█████▋ | 57/100 [00:33<00:25, 1.66 epochs/s, Training Loss=7.95e-6, Validation Loss=1.07e-5, Best Loss=7.24e-6]
Training Fold 6: 57%|█████▋ | 57/100 [00:34<00:25, 1.66 epochs/s, Training Loss=6.11e-6, Validation Loss=9.2e-6, Best Loss=7.24e-6]
Training Fold 6: 58%|█████▊ | 58/100 [00:34<00:25, 1.67 epochs/s, Training Loss=6.11e-6, Validation Loss=9.2e-6, Best Loss=7.24e-6]
Training Fold 6: 58%|█████▊ | 58/100 [00:34<00:25, 1.67 epochs/s, Training Loss=5.5e-6, Validation Loss=8.35e-6, Best Loss=7.24e-6]
Training Fold 6: 59%|█████▉ | 59/100 [00:34<00:24, 1.69 epochs/s, Training Loss=5.5e-6, Validation Loss=8.35e-6, Best Loss=7.24e-6]
Training Fold 6: 59%|█████▉ | 59/100 [00:35<00:24, 1.69 epochs/s, Training Loss=6.04e-6, Validation Loss=8.52e-6, Best Loss=7.24e-6]
Training Fold 6: 60%|██████ | 60/100 [00:35<00:23, 1.73 epochs/s, Training Loss=6.04e-6, Validation Loss=8.52e-6, Best Loss=7.24e-6]
Training Fold 6: 60%|██████ | 60/100 [00:35<00:23, 1.73 epochs/s, Training Loss=7.49e-6, Validation Loss=1.03e-5, Best Loss=7.24e-6]
Training Fold 6: 61%|██████ | 61/100 [00:35<00:23, 1.67 epochs/s, Training Loss=7.49e-6, Validation Loss=1.03e-5, Best Loss=7.24e-6]
Training Fold 6: 61%|██████ | 61/100 [00:36<00:23, 1.67 epochs/s, Training Loss=5.35e-6, Validation Loss=8.32e-6, Best Loss=7.24e-6]
Training Fold 6: 62%|██████▏ | 62/100 [00:36<00:22, 1.67 epochs/s, Training Loss=5.35e-6, Validation Loss=8.32e-6, Best Loss=7.24e-6]
Training Fold 6: 62%|██████▏ | 62/100 [00:37<00:22, 1.67 epochs/s, Training Loss=9.31e-6, Validation Loss=1.34e-5, Best Loss=7.24e-6]
Training Fold 6: 63%|██████▎ | 63/100 [00:37<00:21, 1.69 epochs/s, Training Loss=9.31e-6, Validation Loss=1.34e-5, Best Loss=7.24e-6]
Training Fold 6: 63%|██████▎ | 63/100 [00:37<00:21, 1.69 epochs/s, Training Loss=7.28e-6, Validation Loss=1.03e-5, Best Loss=7.24e-6]
Training Fold 6: 64%|██████▍ | 64/100 [00:37<00:20, 1.74 epochs/s, Training Loss=7.28e-6, Validation Loss=1.03e-5, Best Loss=7.24e-6]
Training Fold 6: 64%|██████▍ | 64/100 [00:38<00:20, 1.74 epochs/s, Training Loss=7.08e-6, Validation Loss=9.78e-6, Best Loss=7.24e-6]
Training Fold 6: 65%|██████▌ | 65/100 [00:38<00:20, 1.71 epochs/s, Training Loss=7.08e-6, Validation Loss=9.78e-6, Best Loss=7.24e-6]
Training Fold 6: 65%|██████▌ | 65/100 [00:38<00:20, 1.71 epochs/s, Training Loss=6.47e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 6: 66%|██████▌ | 66/100 [00:38<00:20, 1.68 epochs/s, Training Loss=6.47e-6, Validation Loss=8.84e-6, Best Loss=7.24e-6]
Training Fold 6: 66%|██████▌ | 66/100 [00:39<00:20, 1.68 epochs/s, Training Loss=5.48e-6, Validation Loss=8.75e-6, Best Loss=7.24e-6]
Training Fold 6: 67%|██████▋ | 67/100 [00:39<00:19, 1.67 epochs/s, Training Loss=5.48e-6, Validation Loss=8.75e-6, Best Loss=7.24e-6]
Training Fold 6: 67%|██████▋ | 67/100 [00:40<00:19, 1.67 epochs/s, Training Loss=5.81e-6, Validation Loss=9.34e-6, Best Loss=7.24e-6]
Training Fold 6: 68%|██████▊ | 68/100 [00:40<00:19, 1.66 epochs/s, Training Loss=5.81e-6, Validation Loss=9.34e-6, Best Loss=7.24e-6]
Training Fold 6: 68%|██████▊ | 68/100 [00:40<00:19, 1.66 epochs/s, Training Loss=5.64e-6, Validation Loss=8.8e-6, Best Loss=7.24e-6]
Training Fold 6: 69%|██████▉ | 69/100 [00:40<00:18, 1.71 epochs/s, Training Loss=5.64e-6, Validation Loss=8.8e-6, Best Loss=7.24e-6]
Training Fold 6: 69%|██████▉ | 69/100 [00:41<00:18, 1.71 epochs/s, Training Loss=5.61e-6, Validation Loss=8.77e-6, Best Loss=7.24e-6]
Training Fold 6: 70%|███████ | 70/100 [00:41<00:17, 1.74 epochs/s, Training Loss=5.61e-6, Validation Loss=8.77e-6, Best Loss=7.24e-6]
Training Fold 6: 70%|███████ | 70/100 [00:41<00:17, 1.74 epochs/s, Training Loss=5.59e-6, Validation Loss=8.73e-6, Best Loss=7.24e-6]
Training Fold 6: 71%|███████ | 71/100 [00:41<00:16, 1.73 epochs/s, Training Loss=5.59e-6, Validation Loss=8.73e-6, Best Loss=7.24e-6]
Training Fold 6: 71%|███████ | 71/100 [00:42<00:16, 1.73 epochs/s, Training Loss=5.2e-6, Validation Loss=8.27e-6, Best Loss=7.24e-6]
Training Fold 6: 72%|███████▏ | 72/100 [00:42<00:15, 1.77 epochs/s, Training Loss=5.2e-6, Validation Loss=8.27e-6, Best Loss=7.24e-6]
Training Fold 6: 72%|███████▏ | 72/100 [00:42<00:15, 1.77 epochs/s, Training Loss=4.96e-6, Validation Loss=8.29e-6, Best Loss=7.24e-6]
Training Fold 6: 73%|███████▎ | 73/100 [00:42<00:15, 1.75 epochs/s, Training Loss=4.96e-6, Validation Loss=8.29e-6, Best Loss=7.24e-6]
Training Fold 6: 73%|███████▎ | 73/100 [00:43<00:15, 1.75 epochs/s, Training Loss=8.42e-6, Validation Loss=1.1e-5, Best Loss=7.24e-6]
Training Fold 6: 74%|███████▍ | 74/100 [00:43<00:15, 1.68 epochs/s, Training Loss=8.42e-6, Validation Loss=1.1e-5, Best Loss=7.24e-6]
Training Fold 6: 74%|███████▍ | 74/100 [00:44<00:15, 1.68 epochs/s, Training Loss=7.01e-6, Validation Loss=8.77e-6, Best Loss=7.24e-6]
Training Fold 6: 75%|███████▌ | 75/100 [00:44<00:14, 1.71 epochs/s, Training Loss=7.01e-6, Validation Loss=8.77e-6, Best Loss=7.24e-6]
Training Fold 6: 75%|███████▌ | 75/100 [00:44<00:14, 1.71 epochs/s, Training Loss=7.68e-6, Validation Loss=1.05e-5, Best Loss=7.24e-6]
Training Fold 6: 76%|███████▌ | 76/100 [00:44<00:14, 1.70 epochs/s, Training Loss=7.68e-6, Validation Loss=1.05e-5, Best Loss=7.24e-6]
Training Fold 6: 76%|███████▌ | 76/100 [00:45<00:14, 1.70 epochs/s, Training Loss=5.92e-6, Validation Loss=8.56e-6, Best Loss=7.24e-6]
Training Fold 6: 77%|███████▋ | 77/100 [00:45<00:13, 1.67 epochs/s, Training Loss=5.92e-6, Validation Loss=8.56e-6, Best Loss=7.24e-6]
Training Fold 6: 77%|███████▋ | 77/100 [00:45<00:13, 1.67 epochs/s, Training Loss=6.28e-6, Validation Loss=8.92e-6, Best Loss=7.24e-6]
Training Fold 6: 78%|███████▊ | 78/100 [00:45<00:13, 1.69 epochs/s, Training Loss=6.28e-6, Validation Loss=8.92e-6, Best Loss=7.24e-6]
Training Fold 6: 78%|███████▊ | 78/100 [00:46<00:13, 1.69 epochs/s, Training Loss=8.65e-6, Validation Loss=1.2e-5, Best Loss=7.24e-6]
Training Fold 6: 79%|███████▉ | 79/100 [00:46<00:12, 1.71 epochs/s, Training Loss=8.65e-6, Validation Loss=1.2e-5, Best Loss=7.24e-6]
Training Fold 6: 79%|███████▉ | 79/100 [00:47<00:12, 1.71 epochs/s, Training Loss=5.45e-6, Validation Loss=8.73e-6, Best Loss=7.24e-6]
Training Fold 6: 80%|████████ | 80/100 [00:47<00:11, 1.72 epochs/s, Training Loss=5.45e-6, Validation Loss=8.73e-6, Best Loss=7.24e-6]
Training Fold 6: 80%|████████ | 80/100 [00:47<00:11, 1.72 epochs/s, Training Loss=5.68e-6, Validation Loss=8.52e-6, Best Loss=7.24e-6]
Training Fold 6: 81%|████████ | 81/100 [00:47<00:11, 1.70 epochs/s, Training Loss=5.68e-6, Validation Loss=8.52e-6, Best Loss=7.24e-6]
Training Fold 6: 81%|████████ | 81/100 [00:48<00:11, 1.70 epochs/s, Training Loss=6.17e-6, Validation Loss=9.13e-6, Best Loss=7.24e-6]
Training Fold 6: 82%|████████▏ | 82/100 [00:48<00:10, 1.73 epochs/s, Training Loss=6.17e-6, Validation Loss=9.13e-6, Best Loss=7.24e-6]
Training Fold 6: 82%|████████▏ | 82/100 [00:48<00:10, 1.73 epochs/s, Training Loss=5.91e-6, Validation Loss=9.42e-6, Best Loss=7.24e-6]
Training Fold 6: 83%|████████▎ | 83/100 [00:48<00:09, 1.75 epochs/s, Training Loss=5.91e-6, Validation Loss=9.42e-6, Best Loss=7.24e-6]
Training Fold 6: 83%|████████▎ | 83/100 [00:49<00:09, 1.75 epochs/s, Training Loss=1.51e-5, Validation Loss=1.81e-5, Best Loss=7.24e-6]
Training Fold 6: 84%|████████▍ | 84/100 [00:49<00:09, 1.77 epochs/s, Training Loss=1.51e-5, Validation Loss=1.81e-5, Best Loss=7.24e-6]
Training Fold 6: 84%|████████▍ | 84/100 [00:49<00:09, 1.77 epochs/s, Training Loss=1.24e-5, Validation Loss=1.62e-5, Best Loss=7.24e-6]
Training Fold 6: 85%|████████▌ | 85/100 [00:49<00:08, 1.79 epochs/s, Training Loss=1.24e-5, Validation Loss=1.62e-5, Best Loss=7.24e-6]
Training Fold 6: 85%|████████▌ | 85/100 [00:50<00:08, 1.79 epochs/s, Training Loss=9.95e-6, Validation Loss=1.28e-5, Best Loss=7.24e-6]
Training Fold 6: 86%|████████▌ | 86/100 [00:50<00:07, 1.79 epochs/s, Training Loss=9.95e-6, Validation Loss=1.28e-5, Best Loss=7.24e-6]
Training Fold 6: 86%|████████▌ | 86/100 [00:50<00:07, 1.79 epochs/s, Training Loss=4.82e-6, Validation Loss=8.35e-6, Best Loss=7.24e-6]
Training Fold 6: 87%|████████▋ | 87/100 [00:50<00:07, 1.81 epochs/s, Training Loss=4.82e-6, Validation Loss=8.35e-6, Best Loss=7.24e-6]
Training Fold 6: 87%|████████▋ | 87/100 [00:51<00:07, 1.81 epochs/s, Training Loss=5.2e-6, Validation Loss=8.57e-6, Best Loss=7.24e-6]
Training Fold 6: 88%|████████▊ | 88/100 [00:51<00:06, 1.82 epochs/s, Training Loss=5.2e-6, Validation Loss=8.57e-6, Best Loss=7.24e-6]
Training Fold 6: 88%|████████▊ | 88/100 [00:52<00:06, 1.82 epochs/s, Training Loss=5.45e-6, Validation Loss=8.97e-6, Best Loss=7.24e-6]
Training Fold 6: 89%|████████▉ | 89/100 [00:52<00:06, 1.83 epochs/s, Training Loss=5.45e-6, Validation Loss=8.97e-6, Best Loss=7.24e-6]
Training Fold 6: 89%|████████▉ | 89/100 [00:52<00:06, 1.83 epochs/s, Training Loss=5.18e-6, Validation Loss=8.46e-6, Best Loss=7.24e-6]
Training Fold 6: 90%|█████████ | 90/100 [00:52<00:05, 1.84 epochs/s, Training Loss=5.18e-6, Validation Loss=8.46e-6, Best Loss=7.24e-6]
Training Fold 6: 90%|█████████ | 90/100 [00:53<00:05, 1.84 epochs/s, Training Loss=7.63e-6, Validation Loss=1.07e-5, Best Loss=7.24e-6]
Training Fold 6: 91%|█████████ | 91/100 [00:53<00:04, 1.87 epochs/s, Training Loss=7.63e-6, Validation Loss=1.07e-5, Best Loss=7.24e-6]
Training Fold 6: 91%|█████████ | 91/100 [00:53<00:04, 1.87 epochs/s, Training Loss=4.97e-6, Validation Loss=8.58e-6, Best Loss=7.24e-6]
Training Fold 6: 92%|█████████▏| 92/100 [00:53<00:04, 1.87 epochs/s, Training Loss=4.97e-6, Validation Loss=8.58e-6, Best Loss=7.24e-6]
Training Fold 6: 92%|█████████▏| 92/100 [00:54<00:04, 1.87 epochs/s, Training Loss=5.7e-6, Validation Loss=8.81e-6, Best Loss=7.24e-6]
Training Fold 6: 93%|█████████▎| 93/100 [00:54<00:03, 1.88 epochs/s, Training Loss=5.7e-6, Validation Loss=8.81e-6, Best Loss=7.24e-6]
Training Fold 6: 93%|█████████▎| 93/100 [00:54<00:03, 1.88 epochs/s, Training Loss=5.98e-6, Validation Loss=9.87e-6, Best Loss=7.24e-6]
Training Fold 6: 94%|█████████▍| 94/100 [00:54<00:03, 1.88 epochs/s, Training Loss=5.98e-6, Validation Loss=9.87e-6, Best Loss=7.24e-6]
Training Fold 6: 94%|█████████▍| 94/100 [00:55<00:03, 1.88 epochs/s, Training Loss=5.64e-6, Validation Loss=9.24e-6, Best Loss=7.24e-6]
Training Fold 6: 95%|█████████▌| 95/100 [00:55<00:02, 1.87 epochs/s, Training Loss=5.64e-6, Validation Loss=9.24e-6, Best Loss=7.24e-6]
Training Fold 6: 95%|█████████▌| 95/100 [00:55<00:02, 1.87 epochs/s, Training Loss=4.85e-6, Validation Loss=8.51e-6, Best Loss=7.24e-6]
Training Fold 6: 96%|█████████▌| 96/100 [00:55<00:02, 1.87 epochs/s, Training Loss=4.85e-6, Validation Loss=8.51e-6, Best Loss=7.24e-6]
Training Fold 6: 96%|█████████▌| 96/100 [00:56<00:02, 1.87 epochs/s, Training Loss=5.45e-6, Validation Loss=9.09e-6, Best Loss=7.24e-6]
Training Fold 6: 97%|█████████▋| 97/100 [00:56<00:01, 1.86 epochs/s, Training Loss=5.45e-6, Validation Loss=9.09e-6, Best Loss=7.24e-6]
Training Fold 6: 97%|█████████▋| 97/100 [00:56<00:01, 1.86 epochs/s, Training Loss=7.33e-6, Validation Loss=9.23e-6, Best Loss=7.24e-6]
Training Fold 6: 98%|█████████▊| 98/100 [00:56<00:01, 1.83 epochs/s, Training Loss=7.33e-6, Validation Loss=9.23e-6, Best Loss=7.24e-6]
Training Fold 6: 98%|█████████▊| 98/100 [00:57<00:01, 1.83 epochs/s, Training Loss=5e-6, Validation Loss=8.67e-6, Best Loss=7.24e-6]
Training Fold 6: 99%|█████████▉| 99/100 [00:57<00:00, 1.88 epochs/s, Training Loss=5e-6, Validation Loss=8.67e-6, Best Loss=7.24e-6]
Training Fold 6: 99%|█████████▉| 99/100 [00:57<00:00, 1.88 epochs/s, Training Loss=8.74e-6, Validation Loss=1.08e-5, Best Loss=7.24e-6]
Training Fold 6: 100%|██████████| 100/100 [00:57<00:00, 1.92 epochs/s, Training Loss=8.74e-6, Validation Loss=1.08e-5, Best Loss=7.24e-6]
Training Fold 6: 100%|██████████| 100/100 [00:57<00:00, 1.73 epochs/s, Training Loss=8.74e-6, Validation Loss=1.08e-5, Best Loss=7.24e-6]
<All keys matched successfully>
Step 5: Compare the predictions¶
To ensure reproducibility, we have included the best performing model from our study.
Load the pre-trained model
model.load_state_dict(torch.load(f"{base_path}/KSL_MultiFold_SixFold.pth"))
<All keys matched successfully>
Check the predictions
input_swir = torch.Tensor(fin_swir)
input_mwir = torch.Tensor(fin_mwir)
input_lwir = torch.Tensor(fin_lwir)
# Ensure the model is in evaluation mode
model.eval()
# Run the forward pass - no need to track gradients here
with torch.no_grad():
predictions = model(input_swir, input_mwir, input_lwir)
# Inverse scaler
meas_ = fin_y * np.array([1e3, 1e1, 1e3])[None, :]
pred_ = predictions * np.array([1e3, 1e1, 1e3])[None, :]
Plot scatter
lowlims = [130, 1.75, -10]
highlims = [320, 3.4, 200]
titles = [r"Slowness", r"Density", r"Gamma-Ray"]
units = [r"$\ \mu \mathrm{s.m^{-1}}$", r"$\ \mathrm{g.cm^{-3}}$", "$\ \mathrm{API}$"]
fig, axs = plt.subplot_mosaic([['A)', 'B)', 'C)']], layout='constrained', figsize=(6, 2.2))
props = dict(boxstyle='round', facecolor='lightblue', edgecolor="lightblue", alpha=0.5)
# Original Data
label = list(axs.keys())
cax = list(axs.values())
for i in range(pred_.shape[1]):
meas = meas_[:, i]
pred = pred_[:, i]
ax = cax[i]
# Compute Metric
metric = MeanSquaredError()
metricr2 = R2Score()
metric.update(torch.Tensor(meas), torch.Tensor(pred))
metricr2.update(torch.Tensor(meas), torch.Tensor(pred))
rmse = np.sqrt(metric.compute().item())
r2 = metricr2.compute().item()
ax.scatter(meas, pred, s=3)
ax.set_title(label[i], loc='left', fontsize='medium')
ax.set_title(titles[i])
textstr = '\n'.join((
r'$R^2=%.3f$' % (r2, ),
r'$RMSE=%.3f$' % (rmse, ),
))
# place a text box in upper left in axes coords
ax.text(0.05, 0.95, textstr, transform=ax.transAxes, fontsize=7,
verticalalignment='top', bbox=props)
ax.axline((0, 0), slope=1, c="r")
ax.set_xlim([lowlims[i], highlims[i]])
ax.set_ylim([lowlims[i], highlims[i]])
ax.set_xlabel("Measured")
if i == 0:
ax.set_ylabel("Predicted")
ax.set_aspect("equal")
plt.show()
# sphinx_gallery_thumbnail_number = -1
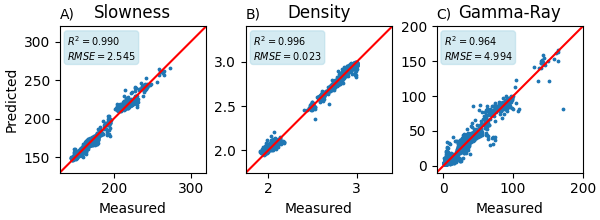
Total running time of the script: (5 minutes 15.254 seconds)